D'un hack au datamesh, l'évolution du data engineering...
Categories:
Conférence Devoxx 2022 D’un hack au datamesh, l’évolution du data engineering… (Simon Maurin et Stéphanie Baltus-Bergamo) chez leboncoin.fr
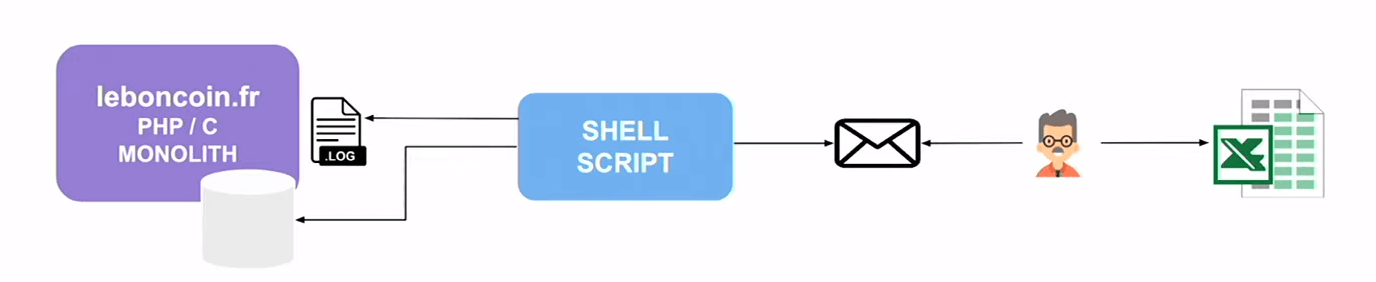
2006, le script shell
2006, shell script qui envoie un emial au gems dumarketing qui font un copie/coller dans un Excel
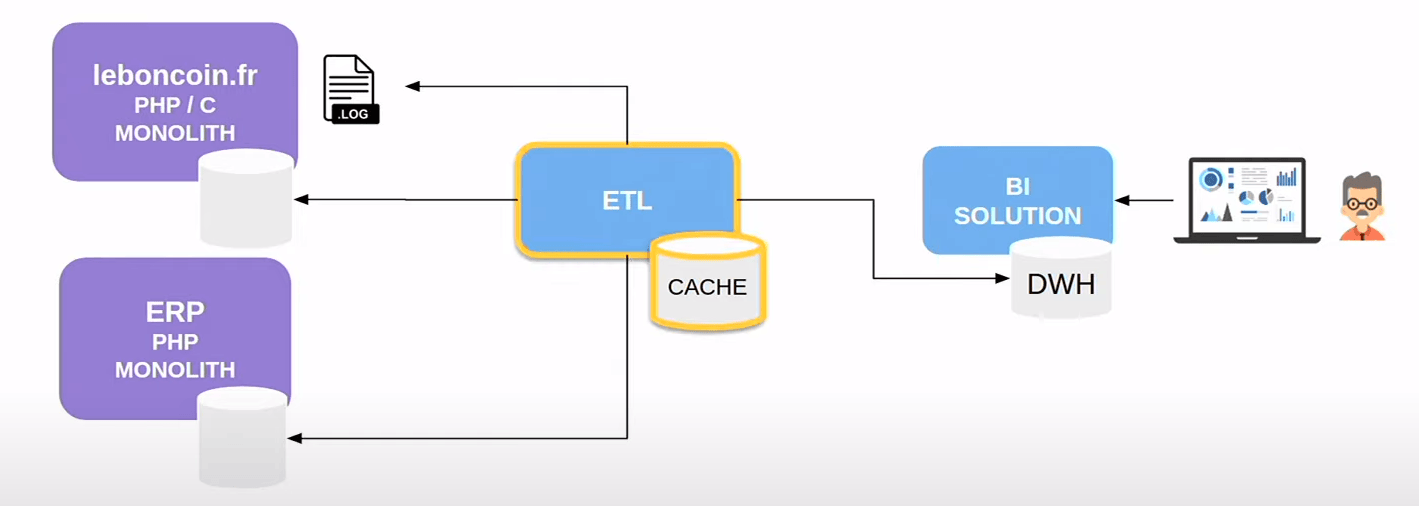
2012, stack de Business Intelligence “by the book”.
Un ETL qui fetch les données dans la source et qui les stocke dans un cache.
Nous transformons les données en un format optimal pour les analyses, puis nous les chargeons dans un data warehouse. Les marketeurs utilisent le data warehouse pour créer des tableaux de bord et prendre de meilleures décisions commerciales.
Les marketeurs sont contents de notre stack analytique, mais nous nous heurtons à des défis d’échelle et de stabilité.
- La quantité de données que nous devons gérer est énorme.
- Les données sont très hétérogènes et doivent être nettoyées et normalisées avant de pouvoir être analysées.
Nous avons besoin de développer des outils et des processus pour gérer l’incrément et la stabilité de notre stack analytique
2015, Big Data
On met les objectifs se ce qu’on souhaite mettre en oeuvre

Nous avons réalisé que nous avions besoin de changer notre approche de l’analyse de données.
-
Notre stack analytique actuel était basé sur des outils traditionnels qui n’étaient pas à la hauteur de la tâche. Nous avions besoin d’une solution qui était distribuée, résiliente et élastique.
-
on veut passer à une approche plateforme, on ne veut plus faire que de la BI, on beut produire des produits data driven (produit créé à partir de la data, soit du Machine learning, ou juste à partir de statistique). Pour cela il faut
- découpler, séparer les responsabilité pour découper notre gros monolithe,
- construire un data lake (stockage objet de data brut), on stocke l’ensemble de la donnée, pas juste celle utilisée à un moment t (pour les besoin du futur)
-
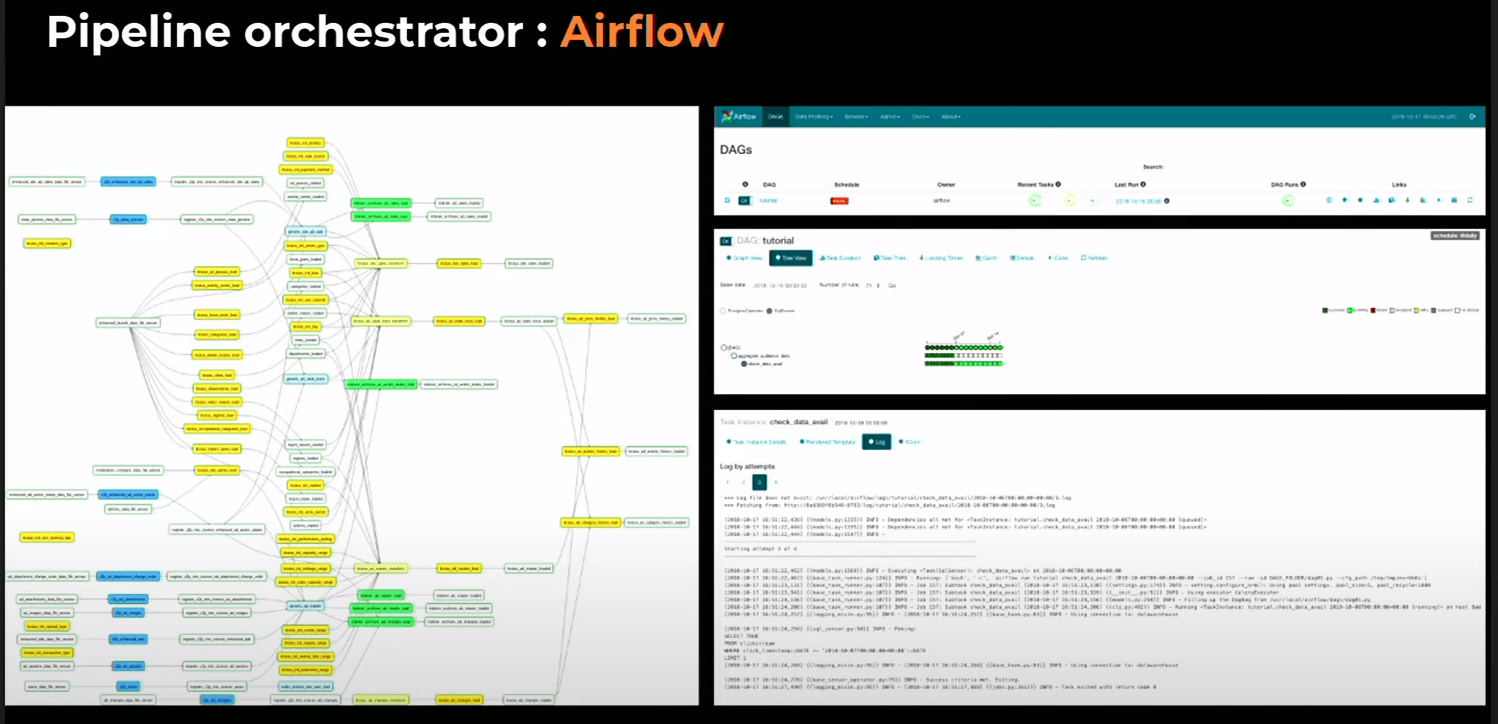
augmenter la résilience. Nous avons choisi d’utiliser Apache Airflow, une plate-forme open source pour le flux de données et la gestion de l’orchestration. Airflow nous a permis de créer un flux de données distribué qui était résilient aux pannes et élastique pour répondre à la demande (airbnb)
On a besoin d’observaility, classique avec datadog.
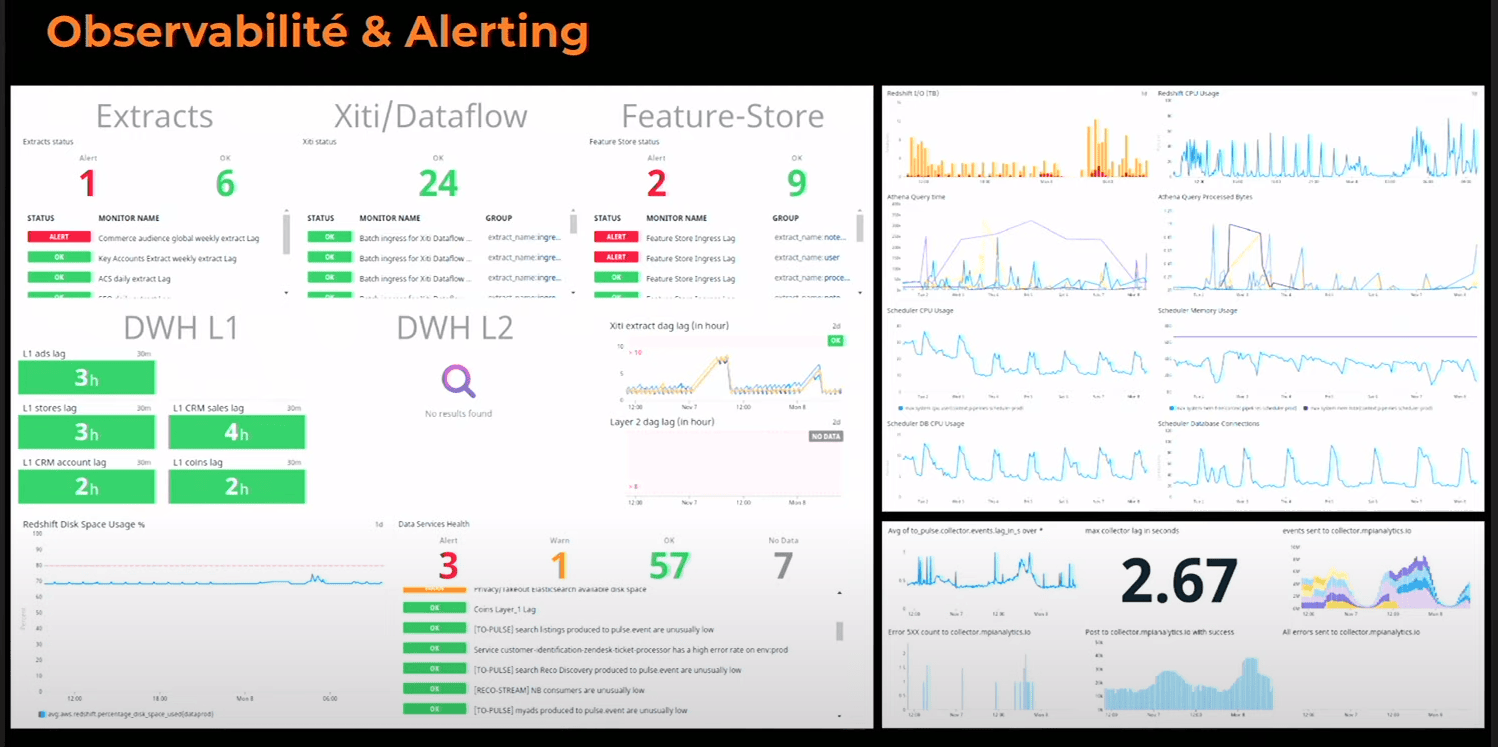
On passe d’un système à J-1 (et donc consistante) à un système Eventual Consistent (différence de lag en fonction de la data) par contre à J+1 tout est chargé et donc consistant

Airflow permet de rejouer nos flux de chargement (en cas de bug). La stratégie d’idempotence, nous a permis de rejouer nos flux de données sans créer de données dupliquées. Cela nous a donné la tranquillité d’esprit de savoir que nos données étaient toujours cohérentes.
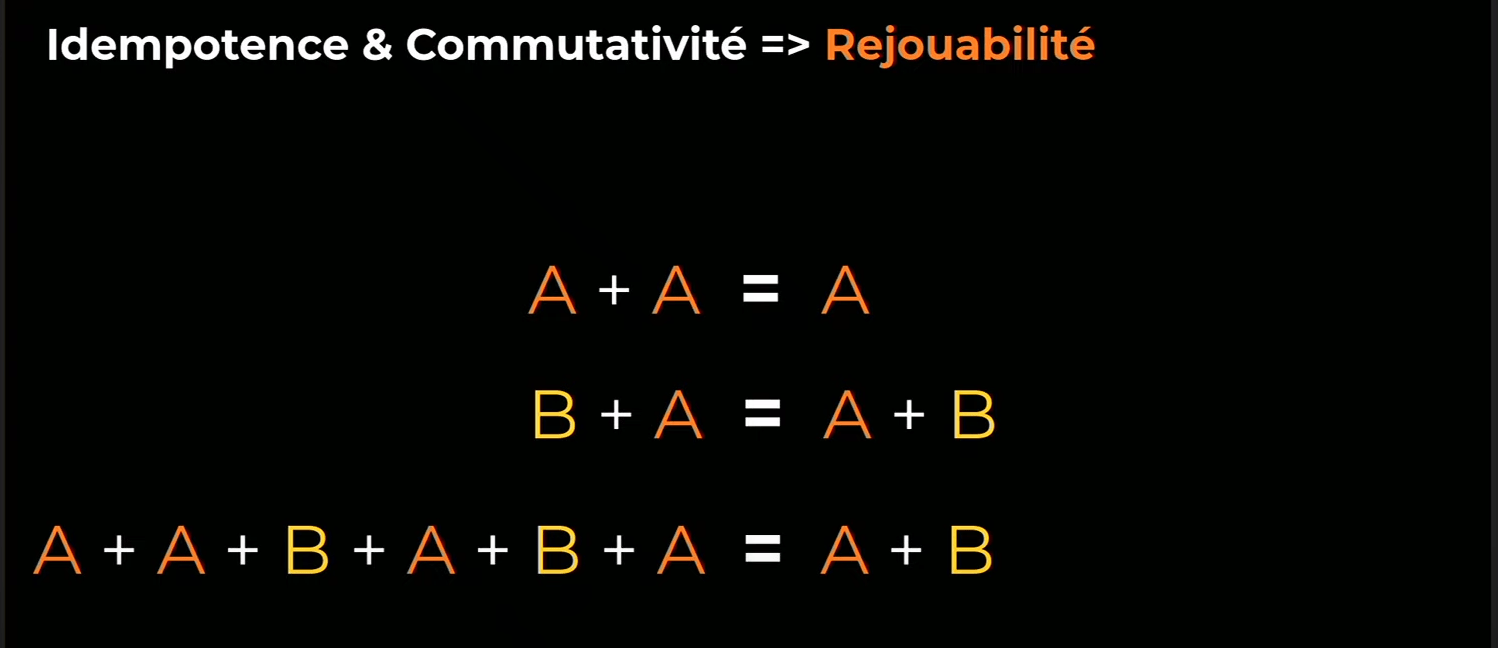
On versionne les objet et on fait des update au lieu de create dans les ordres SQL

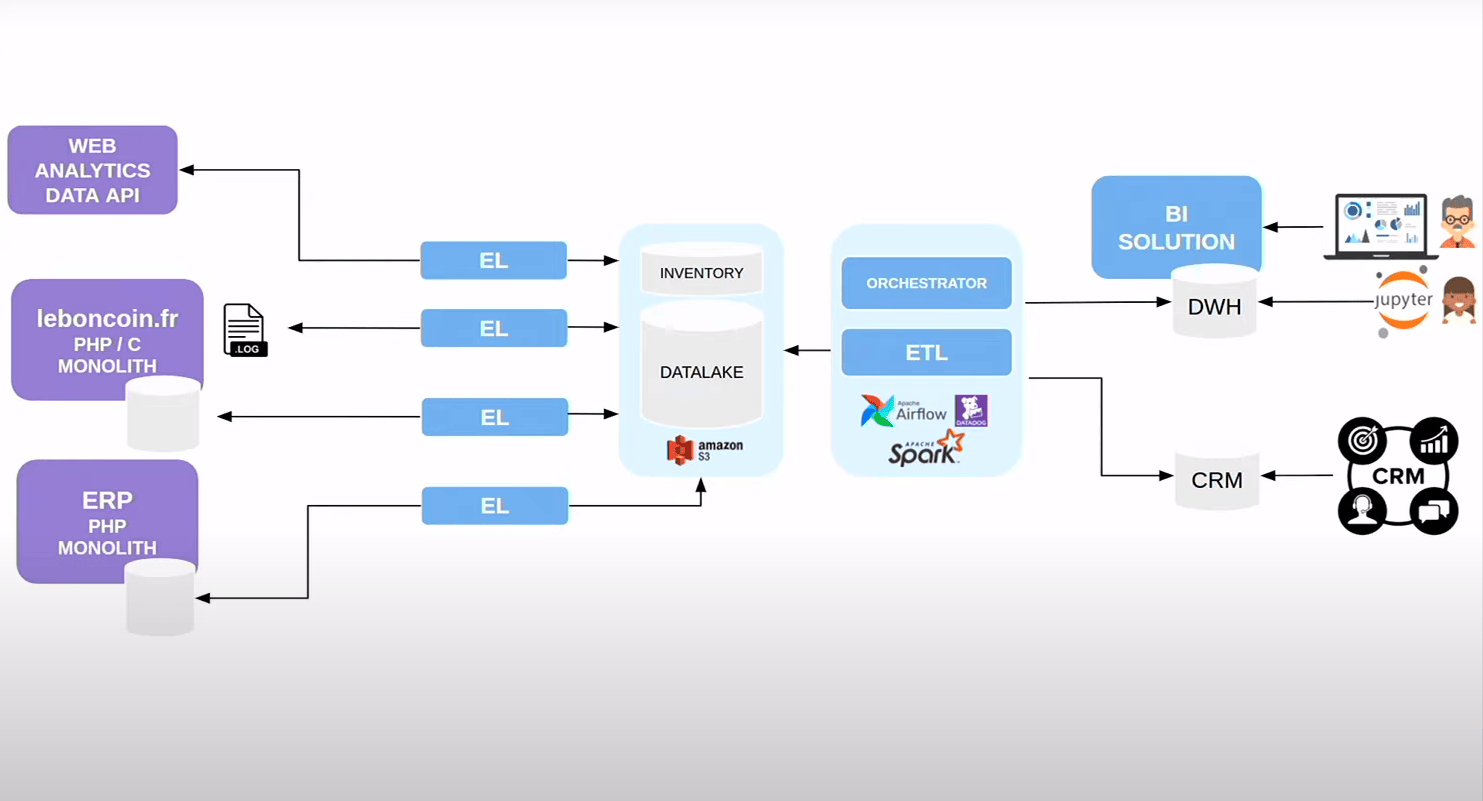
Notre architecture change :
- on continue de faire des extracts dans le data sources, sans business rules, et on stocke dans le data lake (AWS S3)
- ces extractions sont orchestrés via airflow qui lance des scripts SQL et des tâches sur Spark (framework de calcul distribué qui va permttre de distribuer les transfos), monitoré par Datadog
- on a notre solution BI, qui est passé de PostgreSQL à Redshift (AWS). Les marketeurs se pluggent dessus avec Tableau et les Data Scientist requêtes Redshift avec Jupyter notebook
- on a nos premier produits data-driven :
- des stats pour le CRM, pour les télévendeurs qui sait combien le client a déjà déposé d’annonces
- de l’emailing plus ciblé sur le comportement de l’utilisateur
2017, Fetures teams & microservices
L’organisation nus rattrape, on grossit et on arrive à la limite du cycle en V. On passe aussi du monolithe à une archi microservices. Jusqu`à présent, on se source directement dans la DB du monolithe ce qui imposait une contrainte aux dévelopeurs du monolithe qui ne devait pas casser les extractions
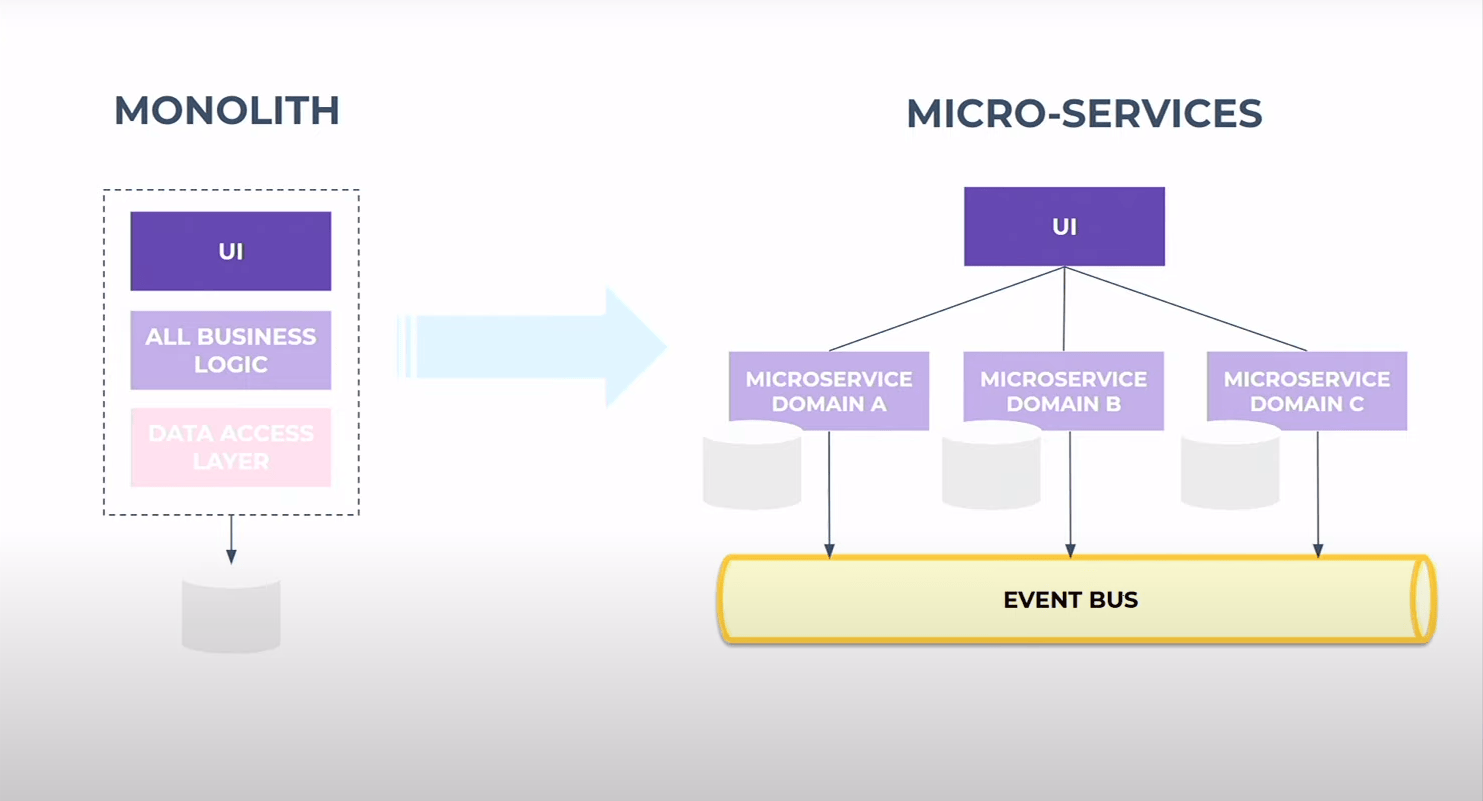
Avec le passage à l’échelle, il faut mettre un contract explicite (et non plus implicite)… On veut passer par un bus d’event. On met les data et backend dans une salle pour négicier les contrats.

L’architecture devient cela :
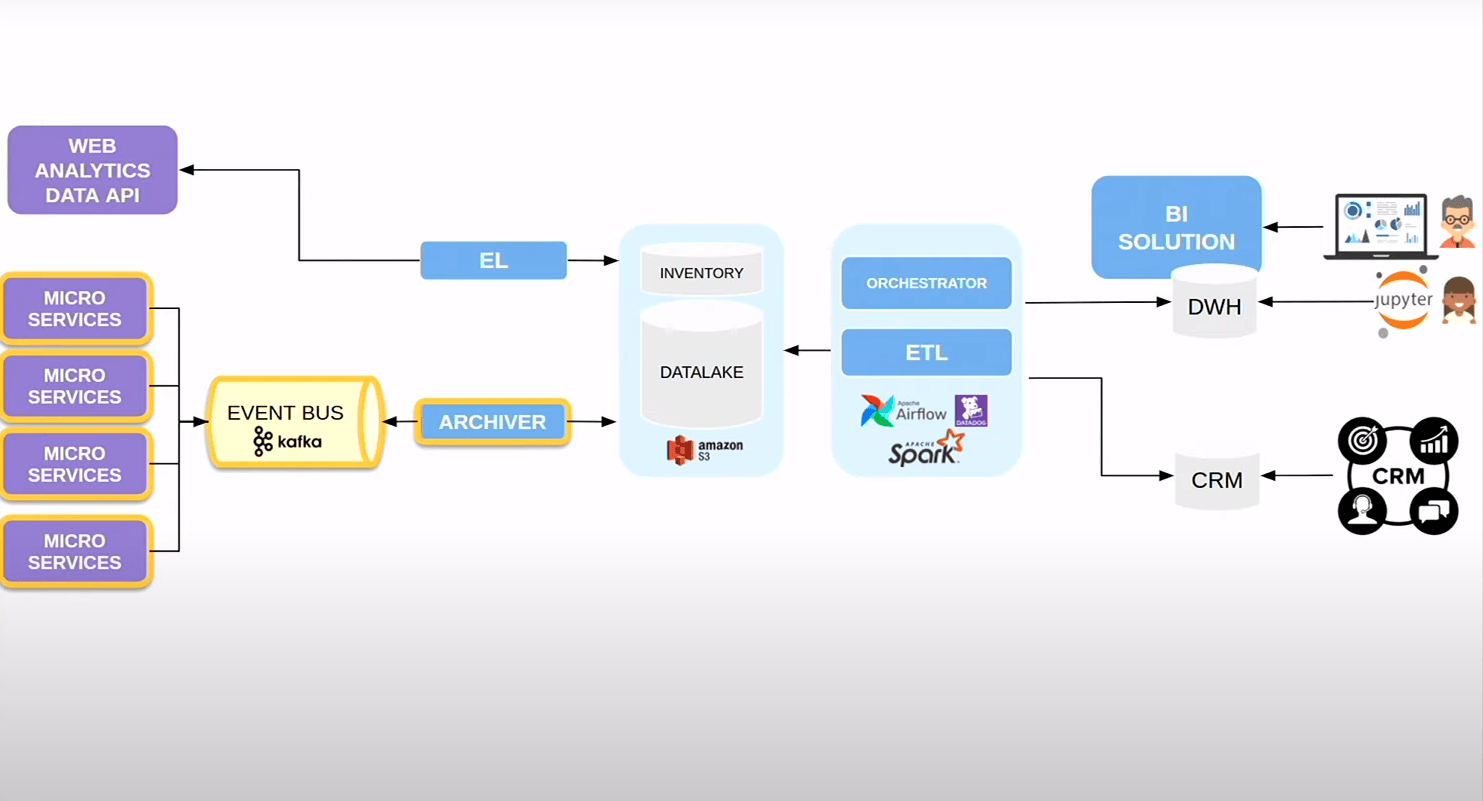
2018, la direction veut un retour sur investissement
On se fait rattraper par la direction qui veut de l’IA, de la valeur ajoutée… (service de recommandation d’annonces)
Un peu de contexte, un data scientiste comment ca travaille :
- on met de la donnée à disposition à travers redshift et S3
- il/elle exploite la data pour voir commenet faire un modèle de recomandation et faire des petits test de modèles
- quand c’est viable, on déploie en PROD et on monitore que ca fonctionne
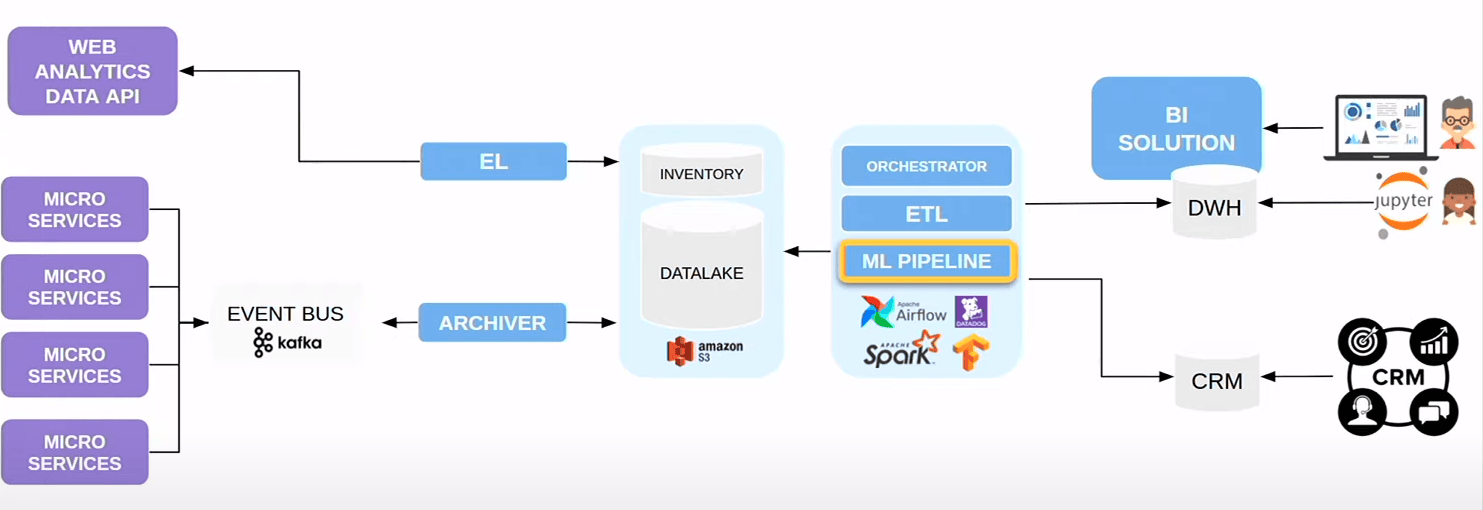
On intègre la partie pipeline avec Airglow qui va permettre d’entrainer tous les modèles des data scientist en ajoutant Tensorflow
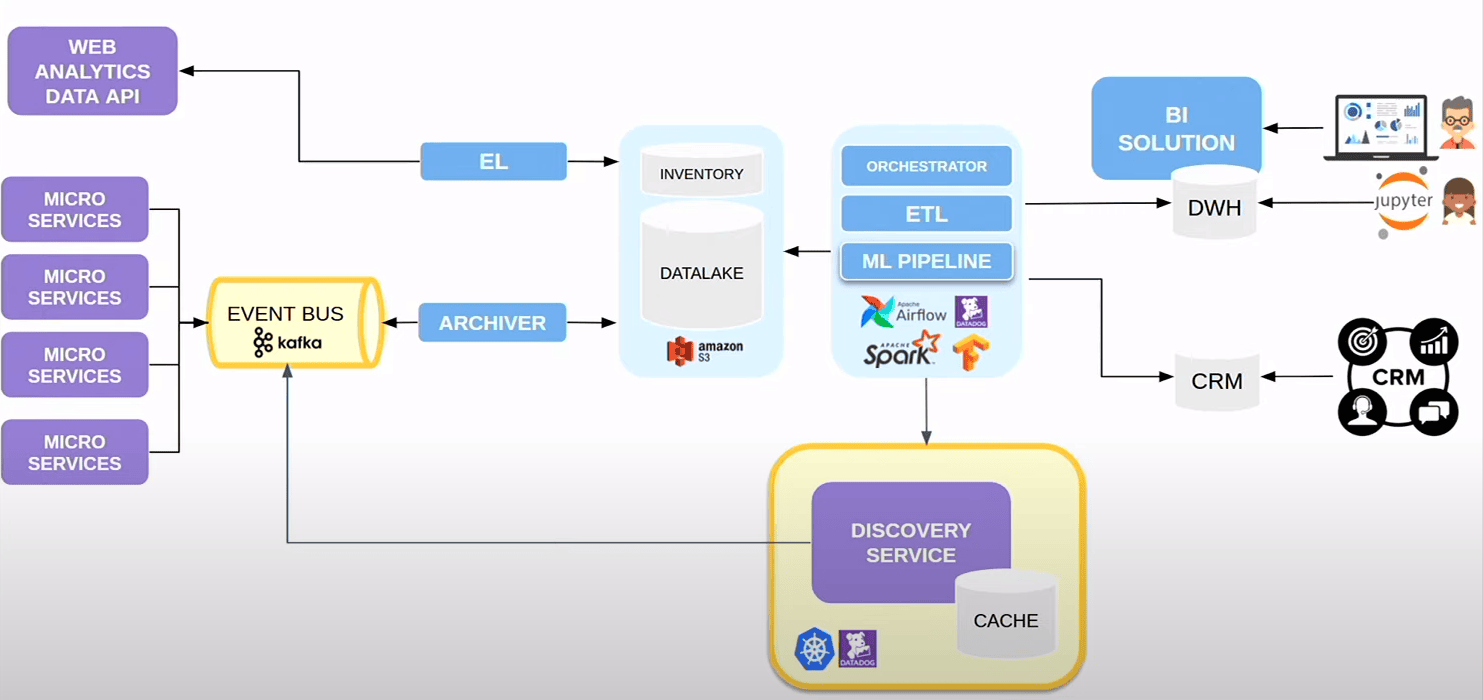
On ajoute un autre microservice sur kunernetes monitoré sur datadog et envoie des événnements dans Kafka pour les recos (c’est un service comme un autre)
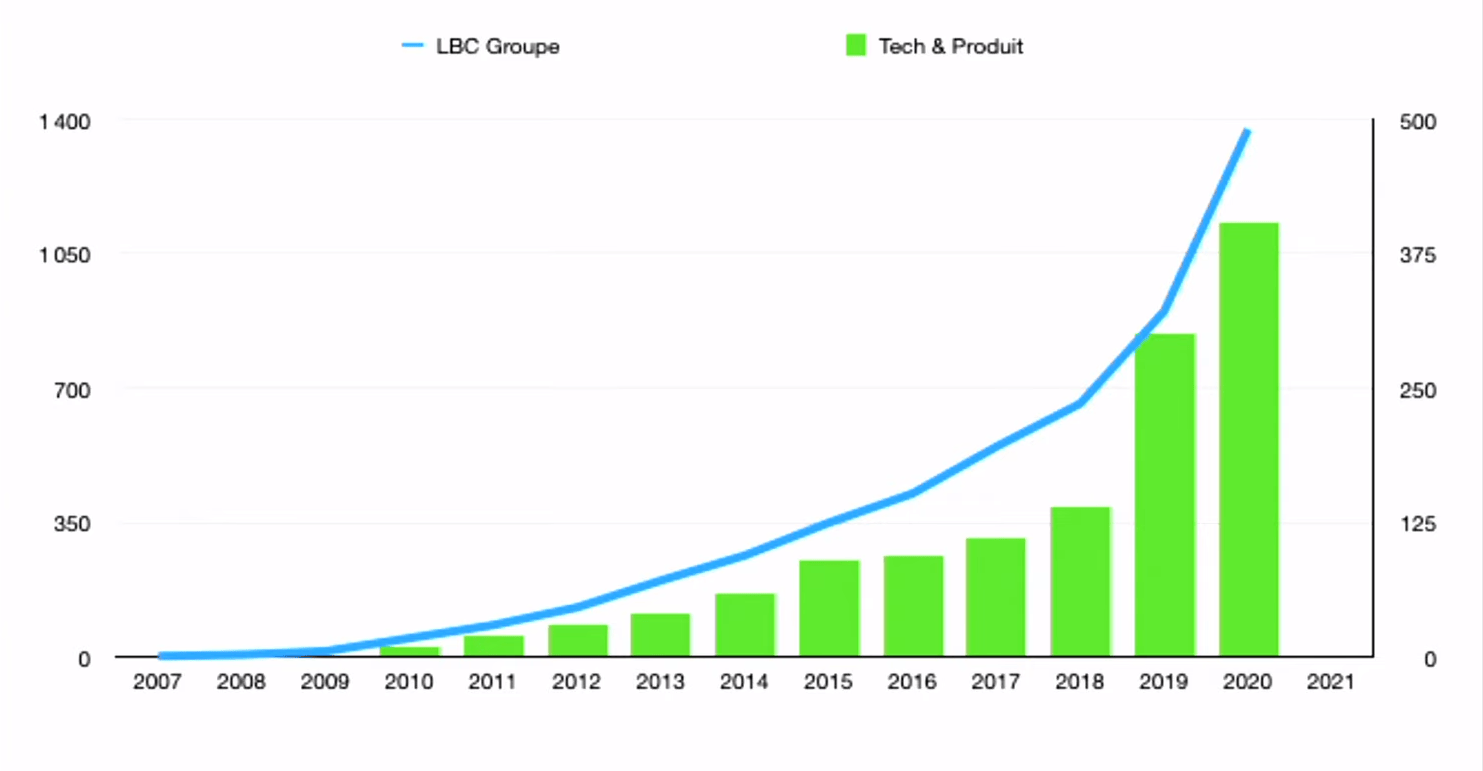
2019, Data Mesh
On se fait une fois de plus rattrapé par l’organisation. Les effctifs ont doublé, les features teams permettent de gérer cela, mais au noveau Data on est resté en équipe centralisé (et ne sont donc pas scalable et deviennent bottleneck)
The term data mesh was first defined by Zhamak Dehghani in 2019[6] while she was working as a principal consultant at the technology company Thoughtworks. How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
L’architecture et l’organsiation en place chez leboncoin est très fréquent eta un problème d’échelle.
- on peut optimiser l’ingestion
- on peut avoir une équipe de spécialiste au milieu qui construise les produits au dessu sdu data lake
- mais pour faire circuler la donnée et les compétences au sein de l’entreprise, cela ne fonctionne pas

Elle propose un contre modèle, qui propose de décentraliser cette approche (l’article est très bien écrit)
- Il faut remettre les compétences data engineering et le code de date à enginering dans les features team, pas de coupure technologique, et faire du Domain Driven Design de bout en bout. Les features teams chez nous opèrent les services, applicatifs, les APIs, les flux d’events mais aussi les pipelines et les dataset qui sont construits on top (qui peuvent être considérés comme des interfaces vers les autres équipes)
- cela s’appuie sur deux éléments
- un socle standard qui permet l’intéropabilité (en haut)
- une plateforme (en bas) qui en gros permet de servir toute la partie infre aui est un peu lourde à mettre en place (flux kafka, bucket S3, cluster Spark à la demande, l’orchestration)
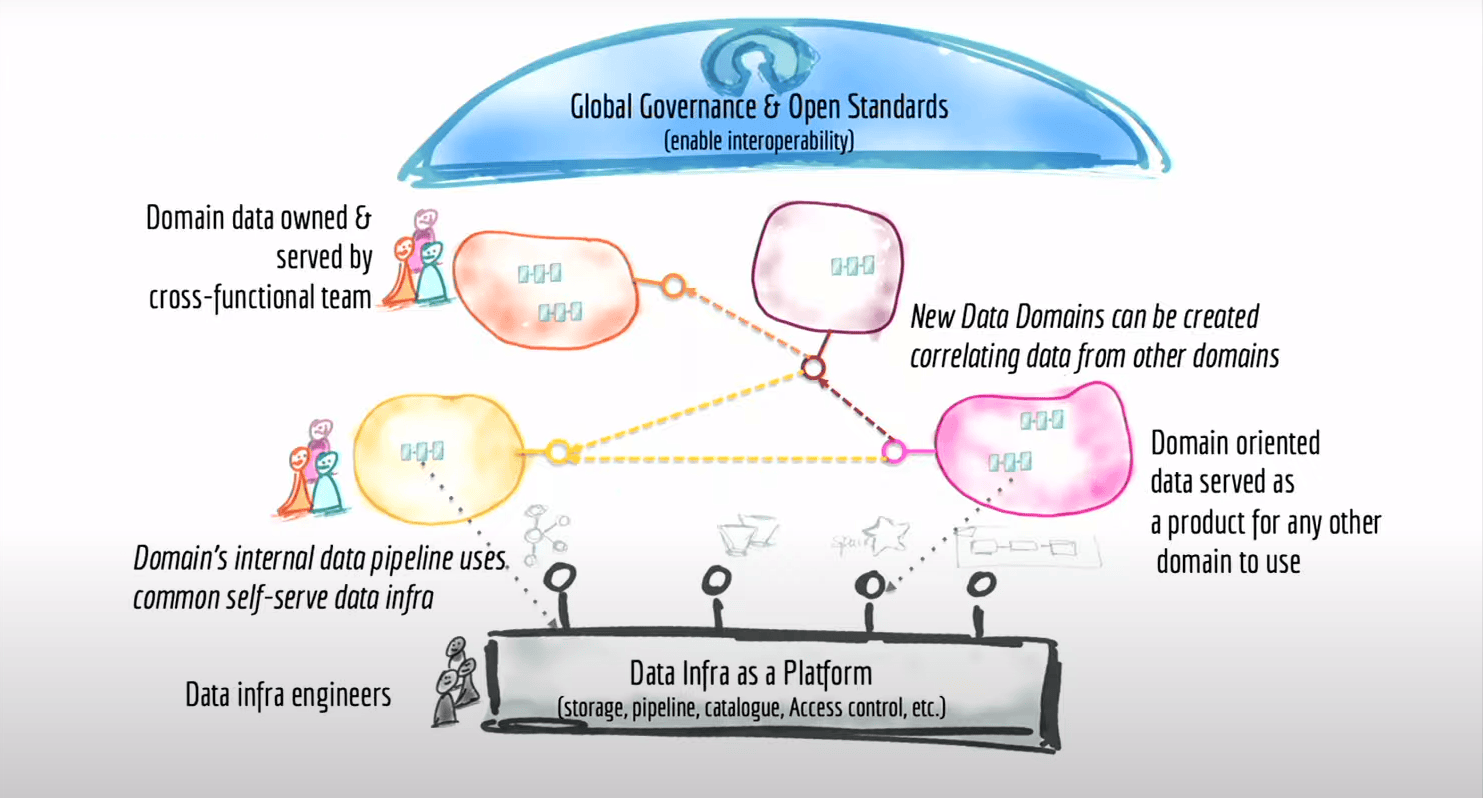
Global governance and open standards
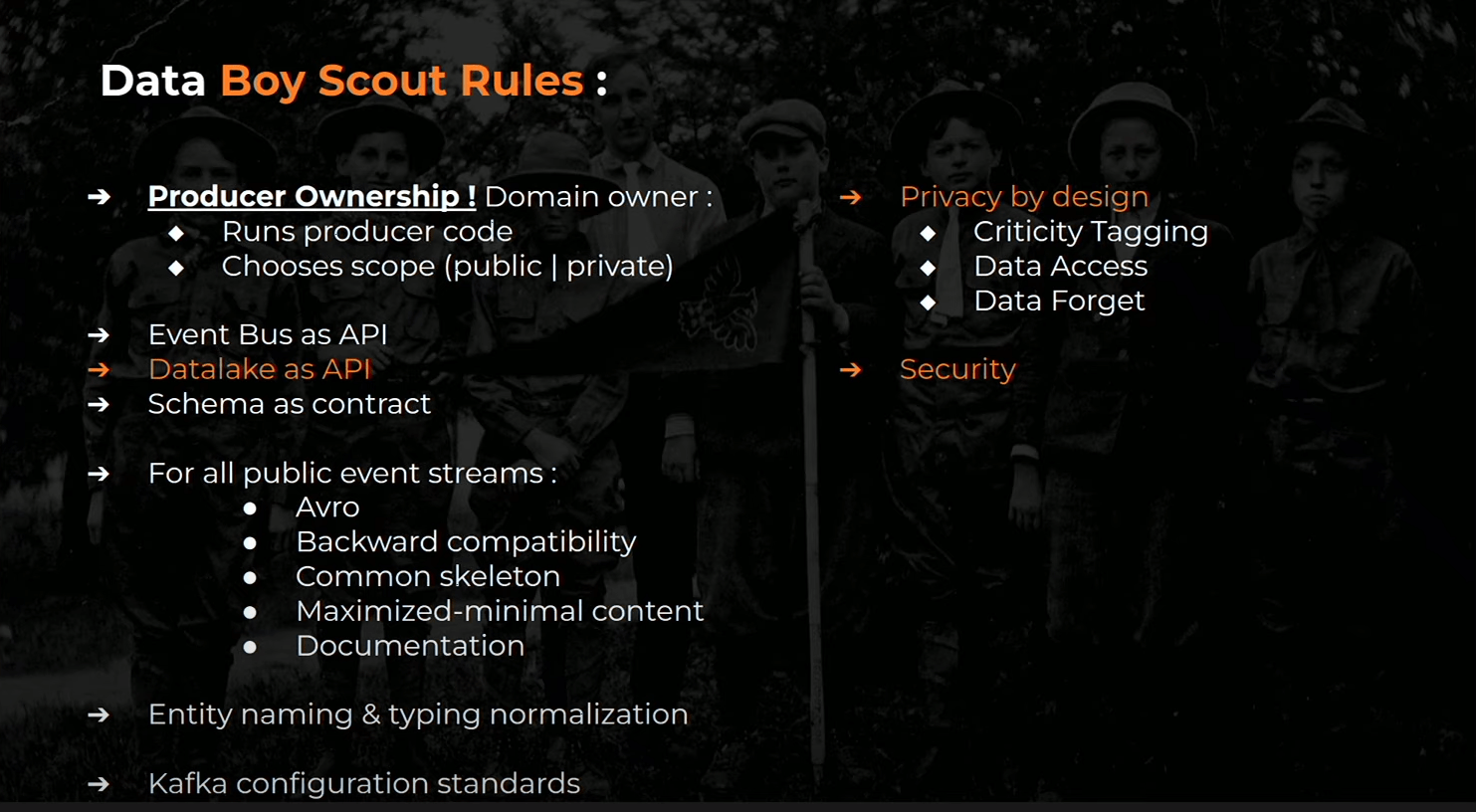
Le socle standard du haut, on l’a presque avec nos règles sur la facon de gérer nos interfaces au desssus du bus d’events, il suffit de les porter jusqu’au Data Lake (S3 et batch)
Côté people
Côté People, on descend les gens qui travaillainet sur le système de reco, pour en faire une vraie feature team, et on injecte des data engineers dans les équipes qui ont des vrais besoin (on ne peut pas faire de big bang). Et les data engineers qui restent centralisés construisent la data Infra as a platform
Investissement sur la Data Infrastructure as a Platform.
On investit assez lourdement sur cette Data Infrastructure as a Platform sur 4 axes
Self-Serve Data Infra

En repo Git avec la CI/CD au dessus sur lequel les DEV viennent déposer des ficheirs déscriptif de l’infrastructure Data qu’ils veulent créér (généralement des topics Kafka) :
- Topologie (flux d’événmenets, job queue, buffer)
- T-shirt sizing
- Scope (public/privé)
- stratégie d’encoding si nécessaire et les schémas
- info sur la criticité des infos personnelles qu’il y a dans le flux
- le domaine auquel le flux se rattache
- l’équipe propriétaire
- la lsite des producteurs et consummers au sens applicatif du terme

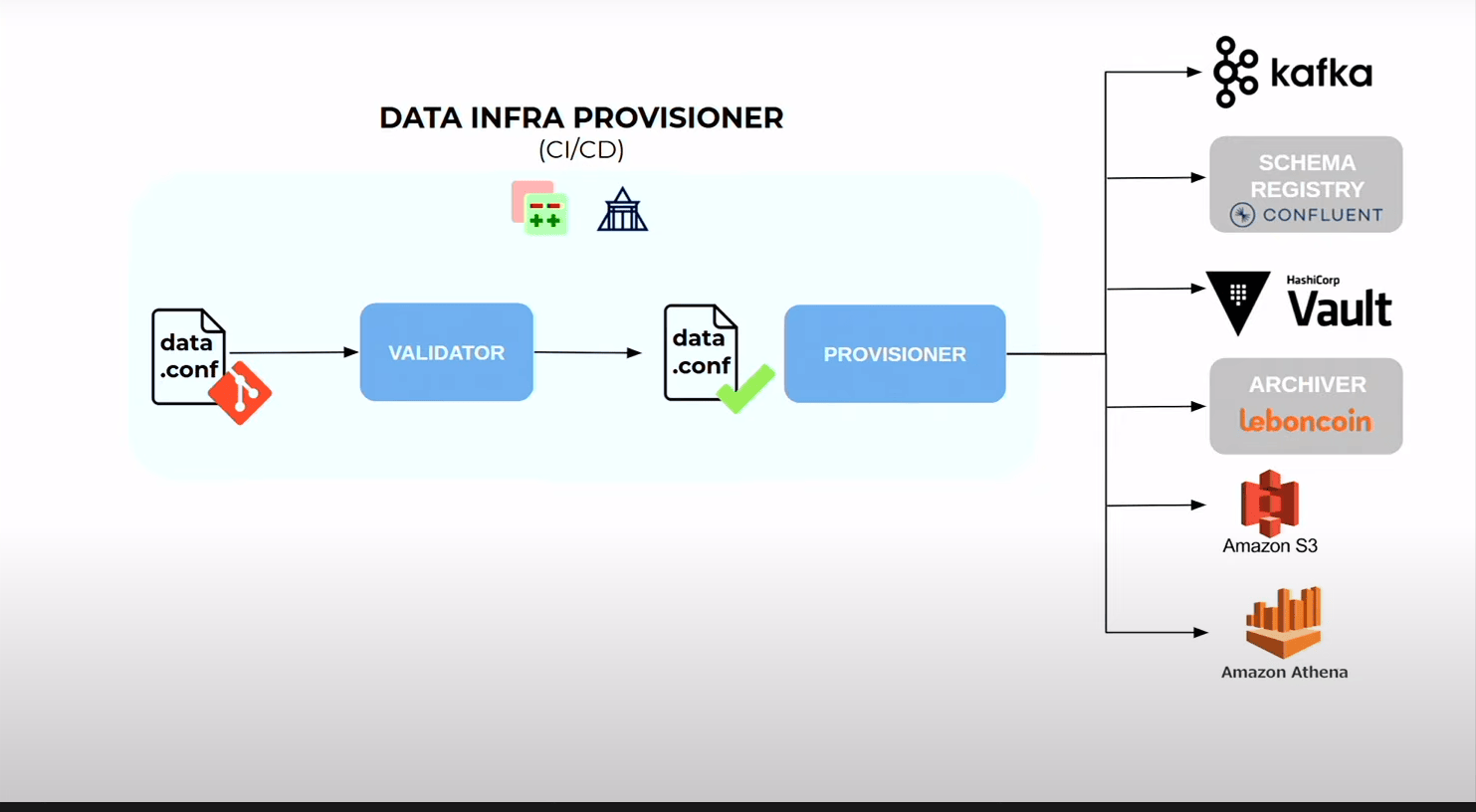
- Cela passe par un validateur qui vérifie que la conf est déployable mais aussi qu’elle respecte les normes de namimg…
- la CD va aller provisionner
- les topics kafka
- schema dans registry
- secrets des applicatifs
- trigger l’archiver pour qu’il vienne archiver ce topic pour qu’il arrive sur S3
- provisionne le bucket S3
- provisionne les schéma Athena (outl qui permet de faire du SQL on top du Data Lake S3)
Très positif car :
- automatise des choses sans valeur ajouté
- renforce les standards (nommage, etc..)
Data Discovery

On a créé un outil de data discovery, un search interne avec qui agrège l’ensemble des sources. Pour le PO ou Data Scientist d’aller trouver les sources pour analyses sur leus domaines métier, soit pour explorer ce qu’ils pourraient utiliser pour construire des modèles
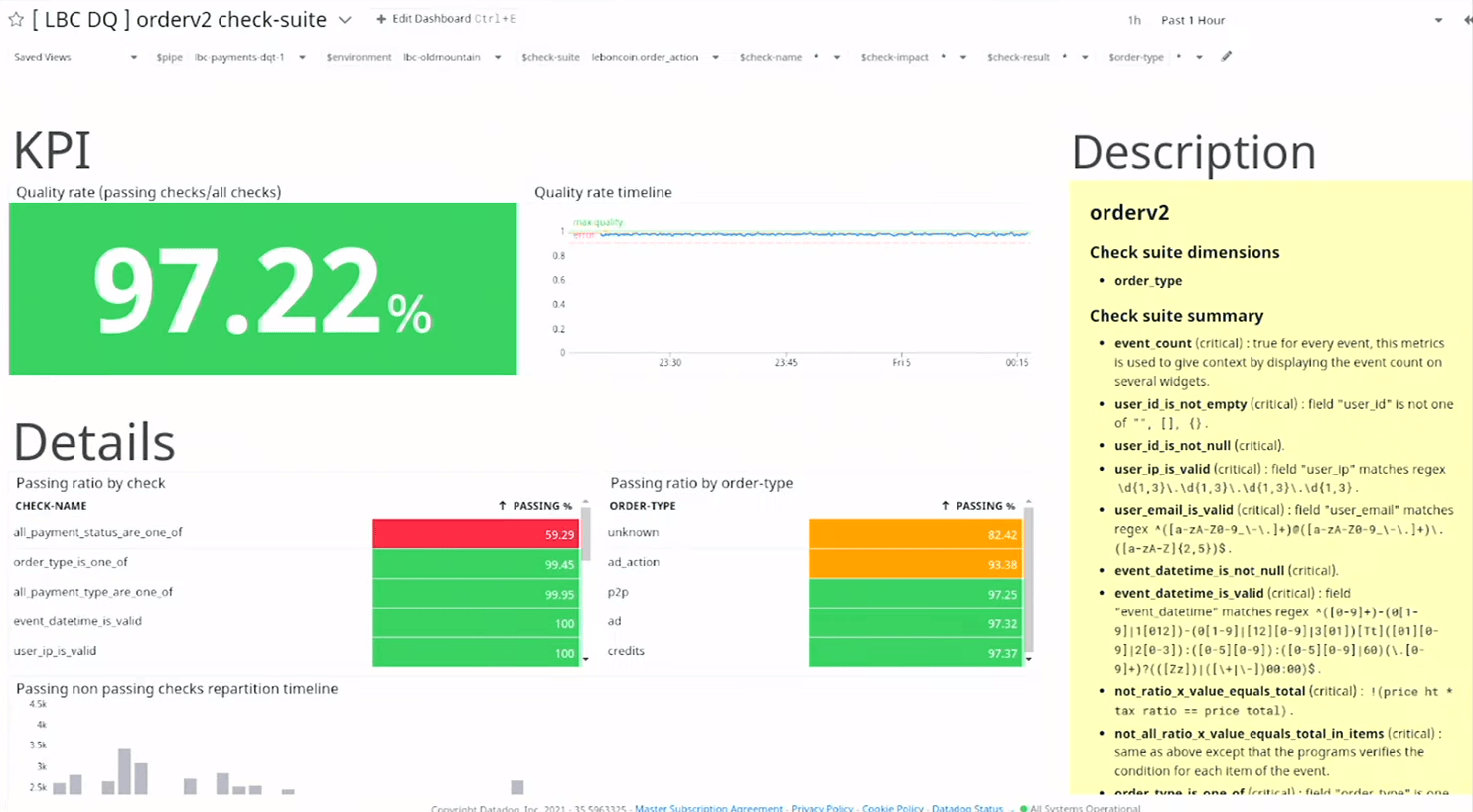
Data Quality Monitoring

On a fait aussi un petit tooling de monitoring de la data quality. Assez simple, petit consummer kafka sur lequel on charge des règles métier, des tests métiers, qu’on va jouer sur les événments et qui envoie des metrics dans Datadog
Permet d’avoir ce genre de dashboard sur les topics. souvent en mode contract testing pour venir tester les assumptions sur les flux qu’on vient consommer des autres équipes
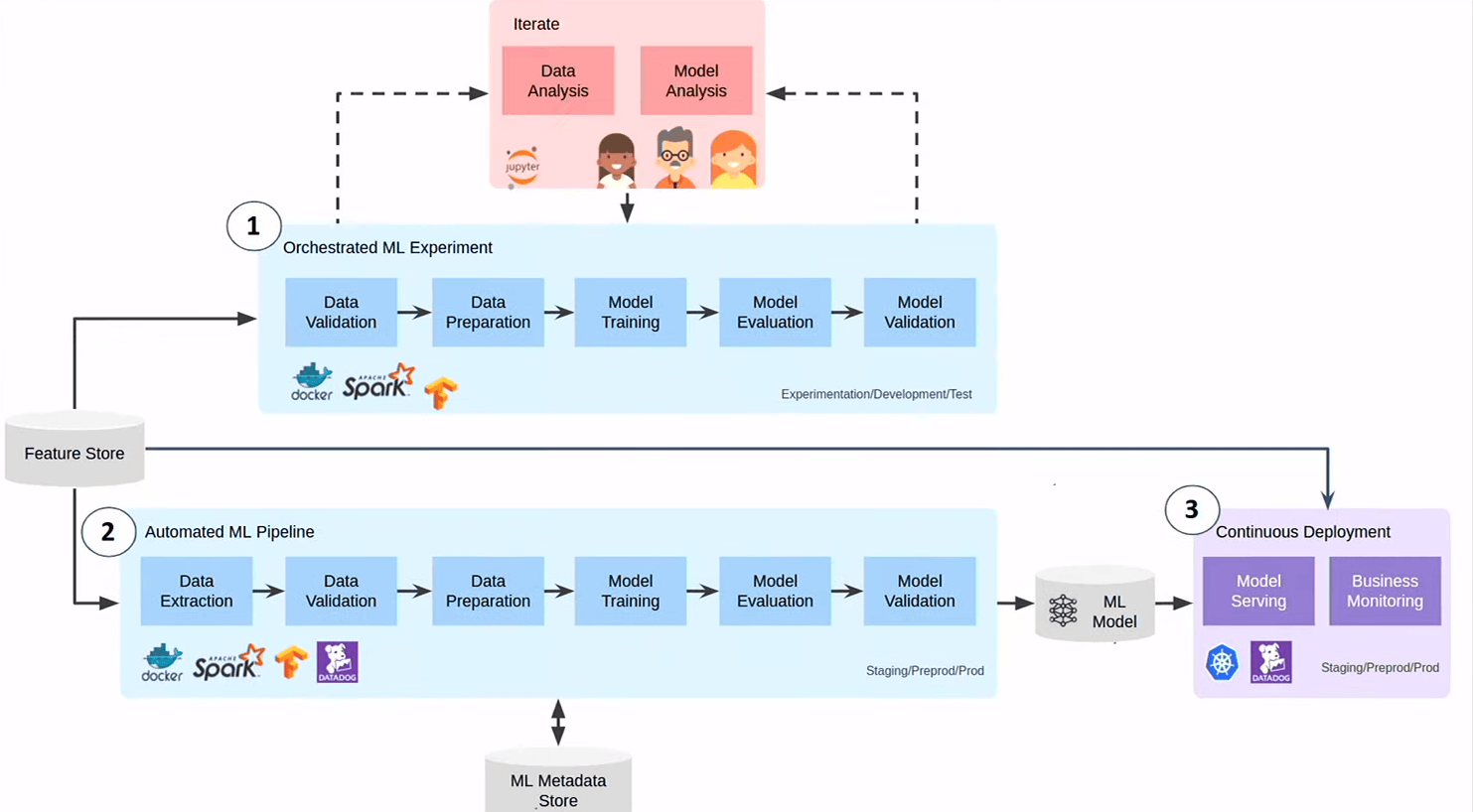
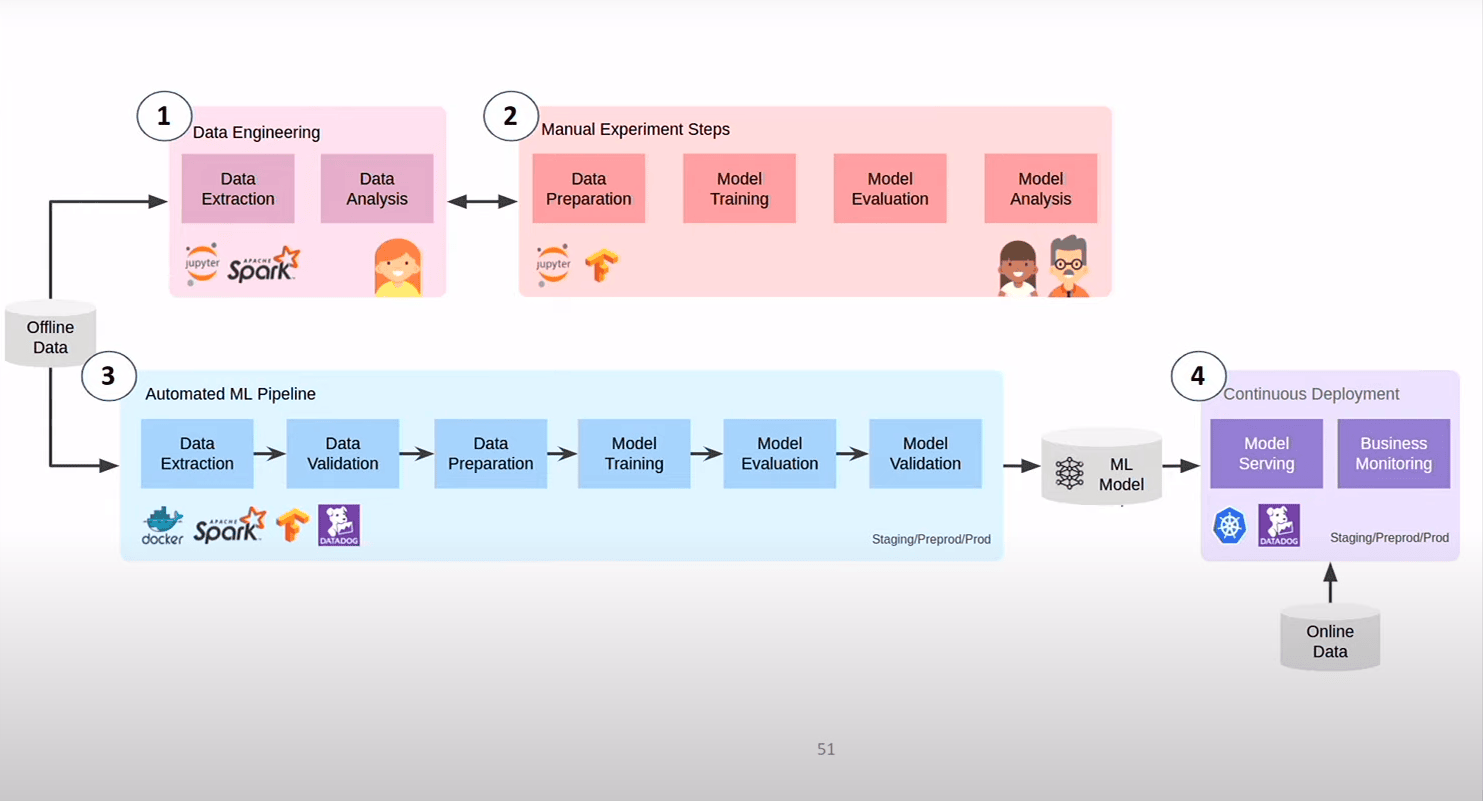
MLOPS
Dernier axe sur lequel on investit encore beaucoup MLOPS = le DEVOPS du ML

- Les Data Engineers (DE) qui s’occupe de fetcher, de faire les premières analyses sur les jeux de données et de les fournir au Data Scietist (DS)
- Les DS explore dessus, crée un modèle
- le modèle créé, ils le redonne au DE ou à des ML Enginner (pareil chez leboncoin) qui écrivent le pipeline qui fait que le modèle se maintient en vie et continue de se déployer
Que moyennement satisfaisant car les DS sont assez loin de l’infra, des pipelines, …on sépare l’OPS des gens qui écrivent la logique . La boucle de feedback n’est pas terrible
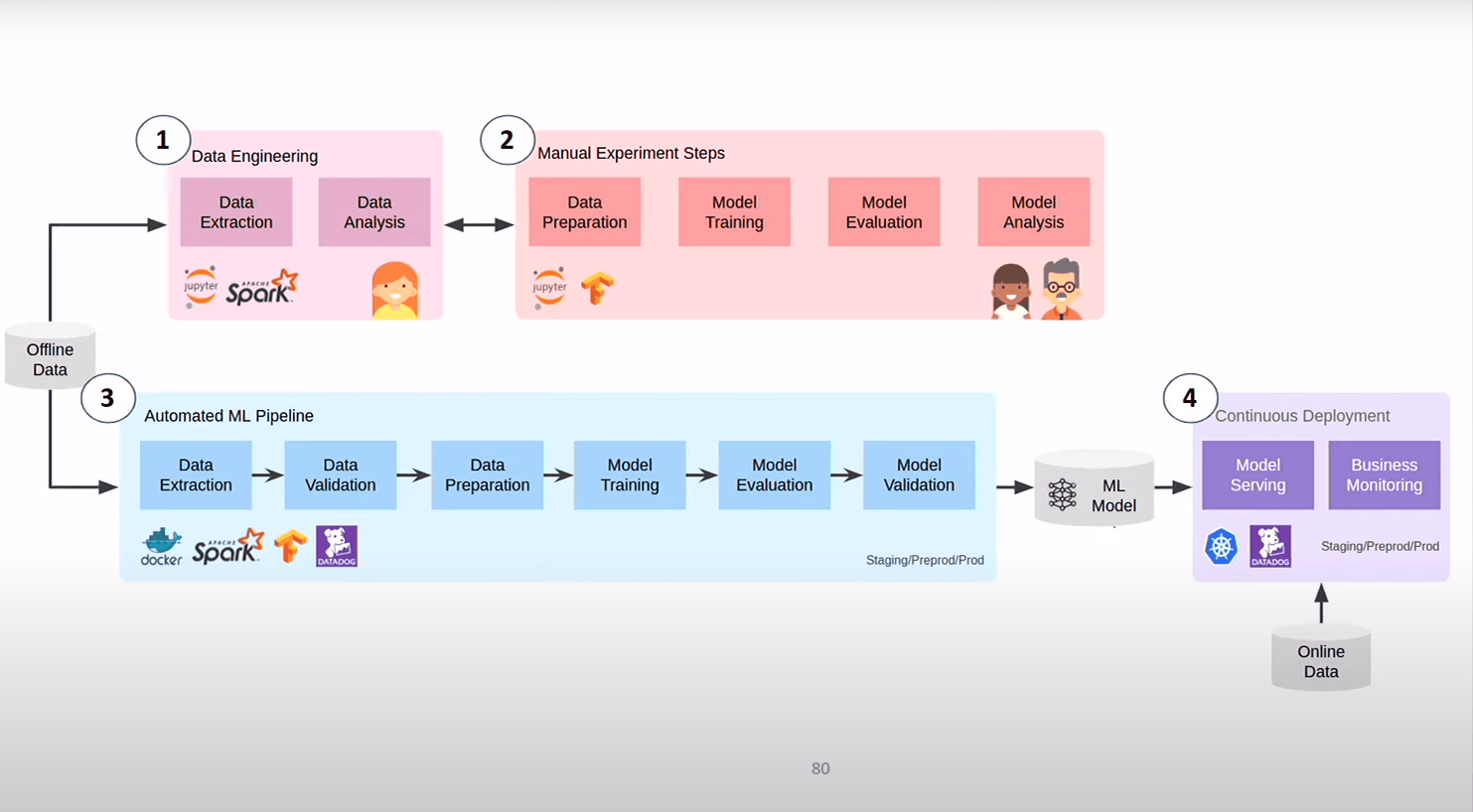
L’idée c’est de les rapprocher.
- On commence la phase d’expérimentation par l’écriture de la piepleine constuits par les DE et les DS qui travaillent ensemble
- la CI/cD déploie automatiquement (dès qu’ils sont “un peu sec”)
On a durant le cycle d’experimemtation le même process que ensuite pendant le déploiement récurrent du modèle (on est plus près des contrainte qu’on va trouver en PROD)
Pour cela :
- On a des pipeleines sur étagère (skeletons)
- on a ajouté à la partie CI/CD qui suit la gestion du code des pipeline une facon de suivre le verionning du dataset, des modèles, et des stats au dessus (on voit l’évolution des stats du modèle dans le temps depuis la période d’expérimentation)
- on a un peu rationnaliser l’accès au feature. Une feature est un KPI qui sert d’entrée à un modèle (je vais recevoir des caillous de DS dans la salle…) au moment du training et aussi potentiellement au moment du service. L’idée du Feature Store c’est que plutôt que de réinventer à chaque fois, on les centralise dans une soltion qui permet de les serbir à la fois en synchrone et en batch