Le futur de la data : Apache Spark 3.1, Delta Lake
Categories:
Le futur de la data : Apache Spark 3.1, Delta Lake et Koalas (Quentin Ambard, Seifeddine Saafi)
https://www.youtube.com/watch?v=YK_tli-jDPs&ab_channel=DevoxxFR
Cette conférence fait le point sur l’écosystème autour de la data et des produits open sources, en particulier autour du framework Spark, cet outil pour faire du calcul distribué su de gros volumes de données
Cette vision est celle portée par Databricks.

Spark Evolution
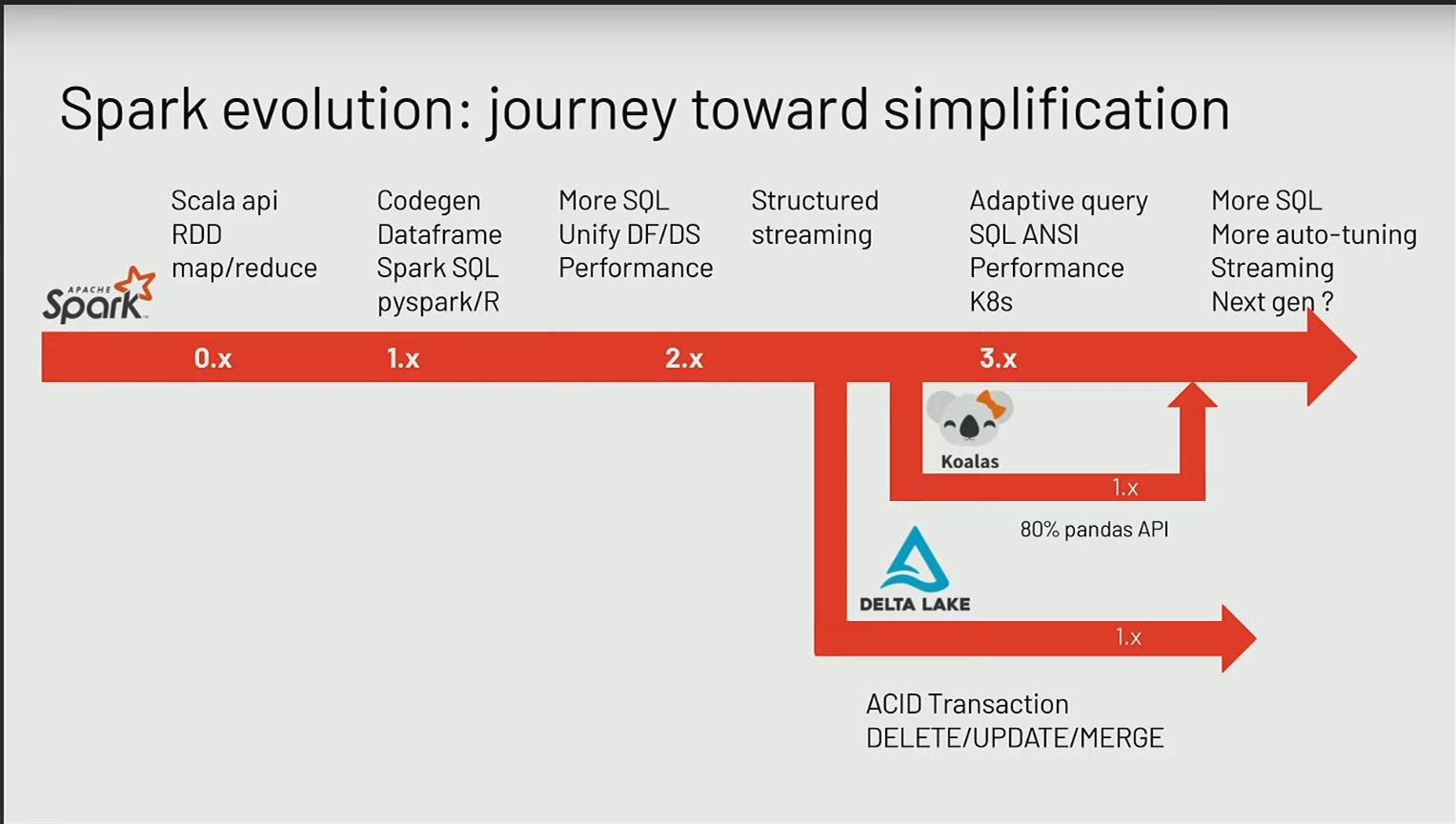
- Spark 0.x : Les débuts de Spark (version 0.x) ont marqué une avancée significative avec un framework exclusivement basé sur Scala et des API MapReduce, surpassant ainsi les limitations de Hadoop. Malgré une application à un niveau plus élevé, l’utilisation de RDD restait complexe, nécessitant une manipulation avancée.
- Spark 1.x : L’évolution vers Spark 1.x a introduit les DataFrames avec des liaisons vers Python et une intégration de SQL généré, réduisant la dépendance aux RDD et simplifiant la programmation en MapReduce.
- Spark 2.x : La version 2 de Spark a unifié le framework avec l’introduction d’API de DataFrames et une intégration complète de SQL, facilitant davantage le processus de transformation des données.
- Spark 3.x : Dans Spark 3.x, la transition des data scientists de pandas à Spark était initialement entravée par l’orientation Scala. Pour remédier à cela, le framework Koalas, à l’origine développé par Databricks, a été intégré dans Spark 3.2. Désormais, Koalas fait partie intégrante de PySpark, permettant aux utilisateurs de réutiliser leur code existant et simplifiant ainsi la transition vers un environnement distribué. Spark 3.x a également introduit des améliorations notables, telles que l’Adaptive Query Tuning, le déploiement sur Kubernetes et la conformité SQL ANSI, simplifiant l’utilisation du framework à un niveau supérieur.
Spark 3 Deep-dive
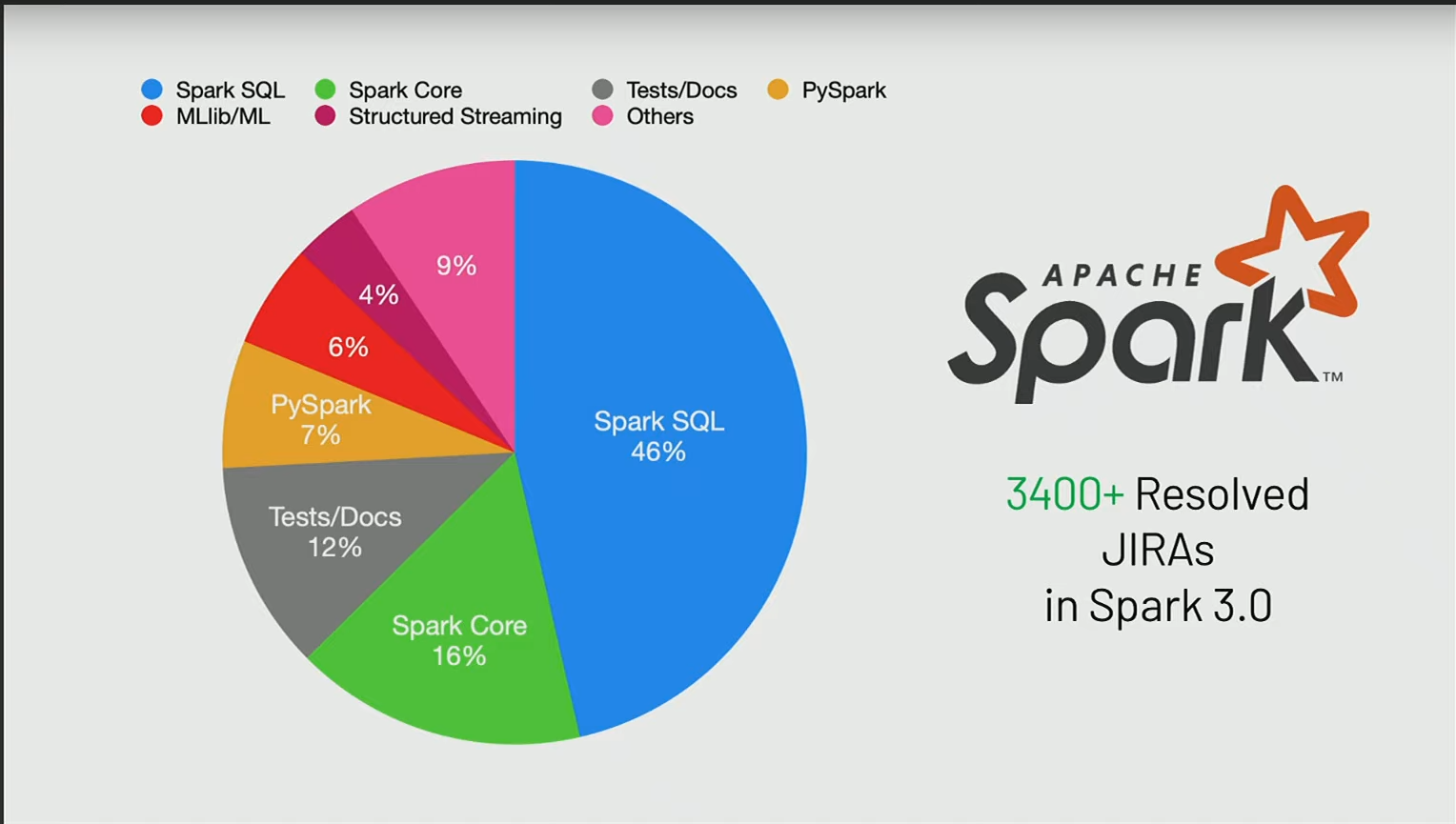
La grande majorité des efforts (Jiras) se concentrent principalement sur le moteur SQL de Spark. Cela englobe les plans d’exécution qui sont à la base de l’interprétation du SQL, quel que soit l’API que vous utilisez.
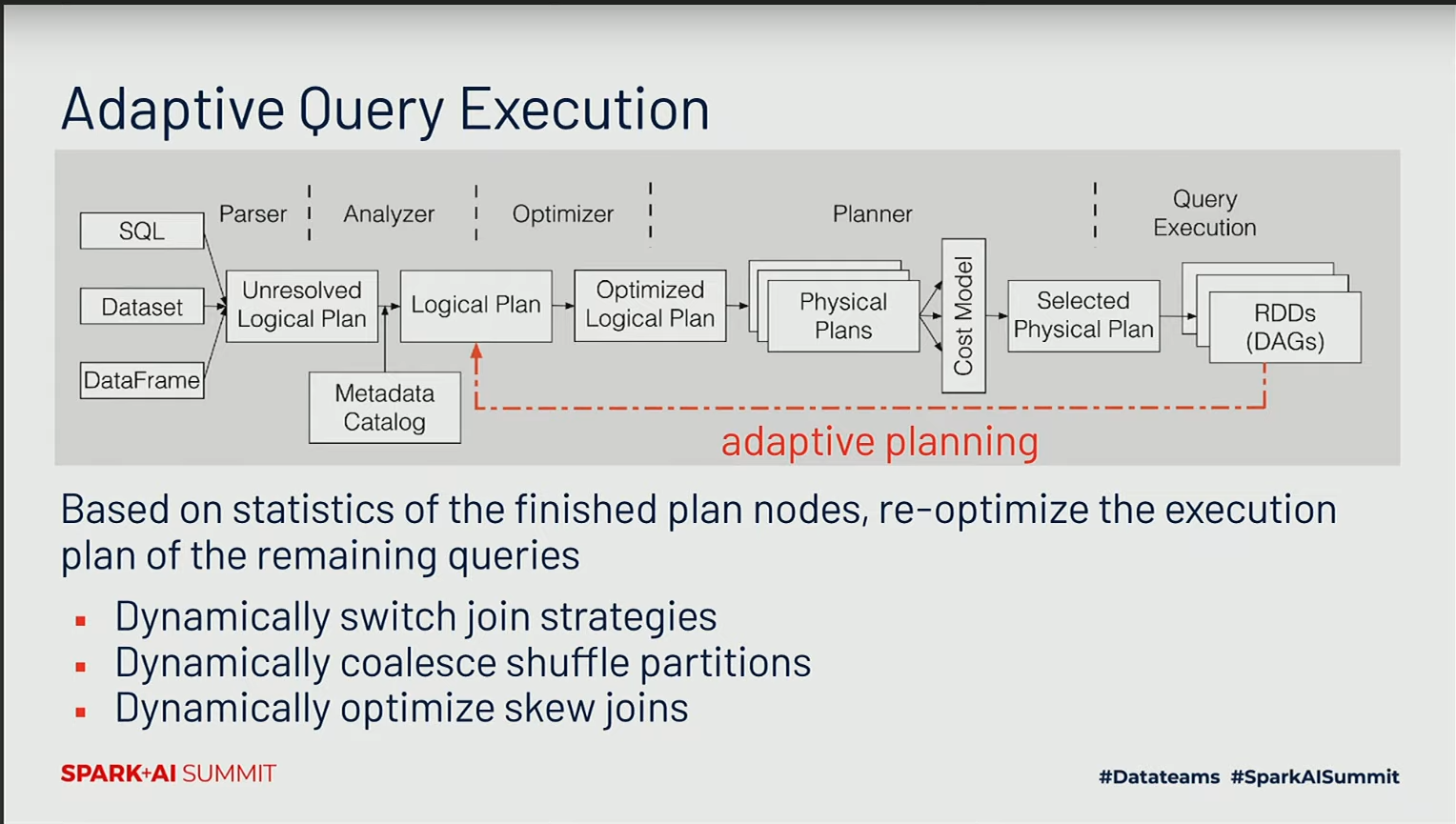
L’amélioration la plus importante sur la performance du moteur SQL sáppelle Adaptative Query Execution.
L’Adaptive Query Execution est une fonctionnalité qui permet au moteur SQL de Spark de s’ajuster dynamiquement en fonction des caractéristiques des données et de l’environnement d’exécution. Cela inclut des ajustements automatiques tels que la sélection dynamique des méthodes d’exécution optimales, la répartition adaptative des tâches, et la gestion dynamique de la mémoire.
Un autre projet majeur est le projet Zen. Son objectif principal est de rendre l’expérience des utilisateurs travaillant avec Python sur Spark plus agréable, en veillant à ce que tout fonctionne correctement et satisfasse leurs besoins.
Ce projet a impliqué une refonte de la documentation et l’ajout de nouvelles fonctionnalités à l’écosystème PySpark.
Slide sur le projet Koala qui sera intégré dans Spark 3.2

Building Data Lake with Spark alone is still painfull
Travailler avec Spark peut être complexe, et de nombreuses problématiques persistent, même lorsque vous utilisez Spark de manière classique, notamment avec le format Parquet.

- L’ajout de données devient complexe lorsque les schémas évoluent.
- Les opérations de mupdate et de delete présentent des défis significatifs.
- En cas d’échec de jobs, la récupération peut être compliquée, avec la possibilité de fichiers partiellement écrits nécessitant une intervention manuelle.

- Mixer des opérations de streaming et des opérations de batch est assez complexe. En général, lors de l’écriture sur un flux, l’ajout ultérieur est difficile car Spark les ignore, pensant qu’il s’agit d’opérations batch erronées.
- La traçabilité pose problème, notamment la conservation de l’historique des opérations.
- La gestion d’un grand nombre de métadonnées devient compliquée avec la croissance du nombre de partitions et de fichiers. Lorsque des tables atteignent des tailles pétaoctets, stocker ces informations dans le metastore peut devenir problématique et la mise à l’échelle devient complexe.

- Les problèmes de performance surgissent fréquemment, notamment avec l’accumulation de nombreux petits fichiers lors de l’utilisation du streaming, ce qui peut entraîner des temps d’ouverture de fichiers supérieurs à l’exécution de la requête.
- La gestion des partitions peut être limitée dans certains cas, notamment lorsque des champs uniques tels que les IDs ne s’y prêtent pas.
- Il peut être difficile d’assurer le contrôle de la qualité des données.

Donc, malgré le fait que Spark devienne plus simple et que de nouveaux moteurs plus opérationnels émergent, la création de data lakes reste un défi.

En résumé, on rencontre des problématiques de fiabilité, de performance, de gouvernance et de qualité des données, ce qui ralentit les projets.
Beaucoup de temps est consacré à la mise en place de l’infrastructure et du cadre opérationnel, au détriment du déploiement de nouveaux projets en production.
Delta Lake
C’est avec ce constat qu’est né le projet Delta Lake, projet qui est en open source depuis quelques deux ou trois ans
Delta vous fournit cette couche transactionnel sur vos fichiers
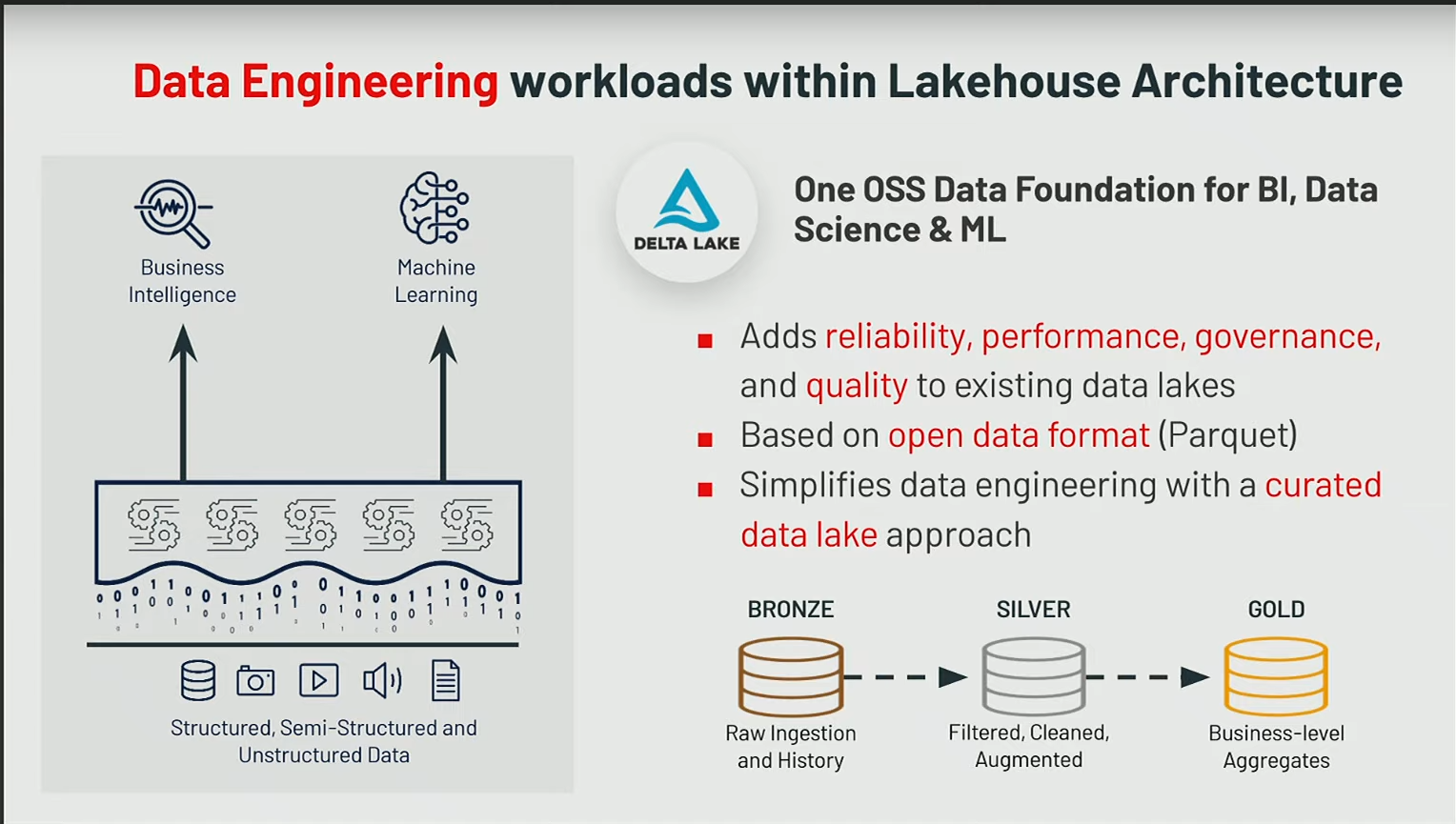
Techniquement, ce sont des fichiers au format Parquet, stockés dans du blob storage comme HDFS, ADLS (Azure Data Lake Storage), AWS S3… L’idée est d’avoir un système qui fait une abstraction sur es fichiers stockés :
- les fichiers qui sont stockés sont en parquet
- mais vous ne savez pas trop comment ils sont, vous ne connaissez pas trop le layout, ce n’est pas votre problème
- le moteur vient s’occuper de gérer pour vous toute ce partie-là (file compaction, updtae, merge, …)
Delta Lake offre des fonctionnalités comme :
- remonter dans le temps une version donnée
- faire des clones zéro-copie
- suivre les changements dans votre table delta
Delta Lake et les challenges liés à Spark

Reliability & Transactions ACID
Delte Lake offre plein de fonctionnalités comme ça qui vient de vous simplifier la vie et faire en sorte que vous puissiez avoir quelqu’un qui fait un delete pendant que vous avez vos flux d’insert qui continue en streaming en consommant des messages Kafka en parallèle sans que cela ne pose de problème. Si par malchance vous avez deux delete en même temps sur le même fichier, un des deux delete provoque une erreur, puis un roll back sur la transaction qui échoue avec un message erreur qui sera logué et sans donnée corrompue.
Cette notion de transaction ACID augmente donc la fiabilité
Performance
Les problème de performance grâce à des système d’indexing, qui est en fait c’est :
- de la colocalisation de données similaires (clustering)
- couplée à des statistiques sur les fichiers
Lorsque vous appliquez un filtre dans une instruction SELECT, toutes les informations sur les fichiers sont stockées dans les métadonnées des logs Delta. Il n’y a pas de problème d’évolutivité car les logs eux-mêmes sont contenus dans un fichier Parquet.
Ce concept est particulièrement intéressant dans le domaine du big data. La gestion des métadonnées devient une problématique de big data lorsque vous manipulez des millions de fichiers, et Delta contribue à résoudre cette complexité en stockant ces informations de manière efficace.
Lors d’un select sur une table au format delta il y a deux jobs qui tournent:
- le premier job il vient chercher les métadatas pour savoir ce qu’il faut qu’il analyse
- et le second job il fait vraiment l’analyse en soi-même
Gouvernance & Qualité
Il existe en particulier les expectations qui sont des contraintes sur les tables (exemple entier non nul). Un insert qui ne respecte pas la contrainte fera échouer le job.
Spark 3, Delta Lake… vers une architecture Lakehouse

Evolution des datawarehouse
En remontant dans l’historique des data warehouses :
- Les data warehouses sont des technologies présentes depuis les années 80, ayant émergé avec des acteurs tels qu’IBM, Teradata, et Oracle.
- Au fil du temps, l’évolution a conduit à l’émergence de bases de données plus performantes, notamment avec des architectures de type colonnes, comme le cas de Vertica.
- Plus récemment, avec l’avènement des fournisseurs de services cloud, de nouveaux data warehouses plus performants ont été introduits.
Globalement, l’accent a été mis sur l’élasticité dans le cloud et des performances accrues.
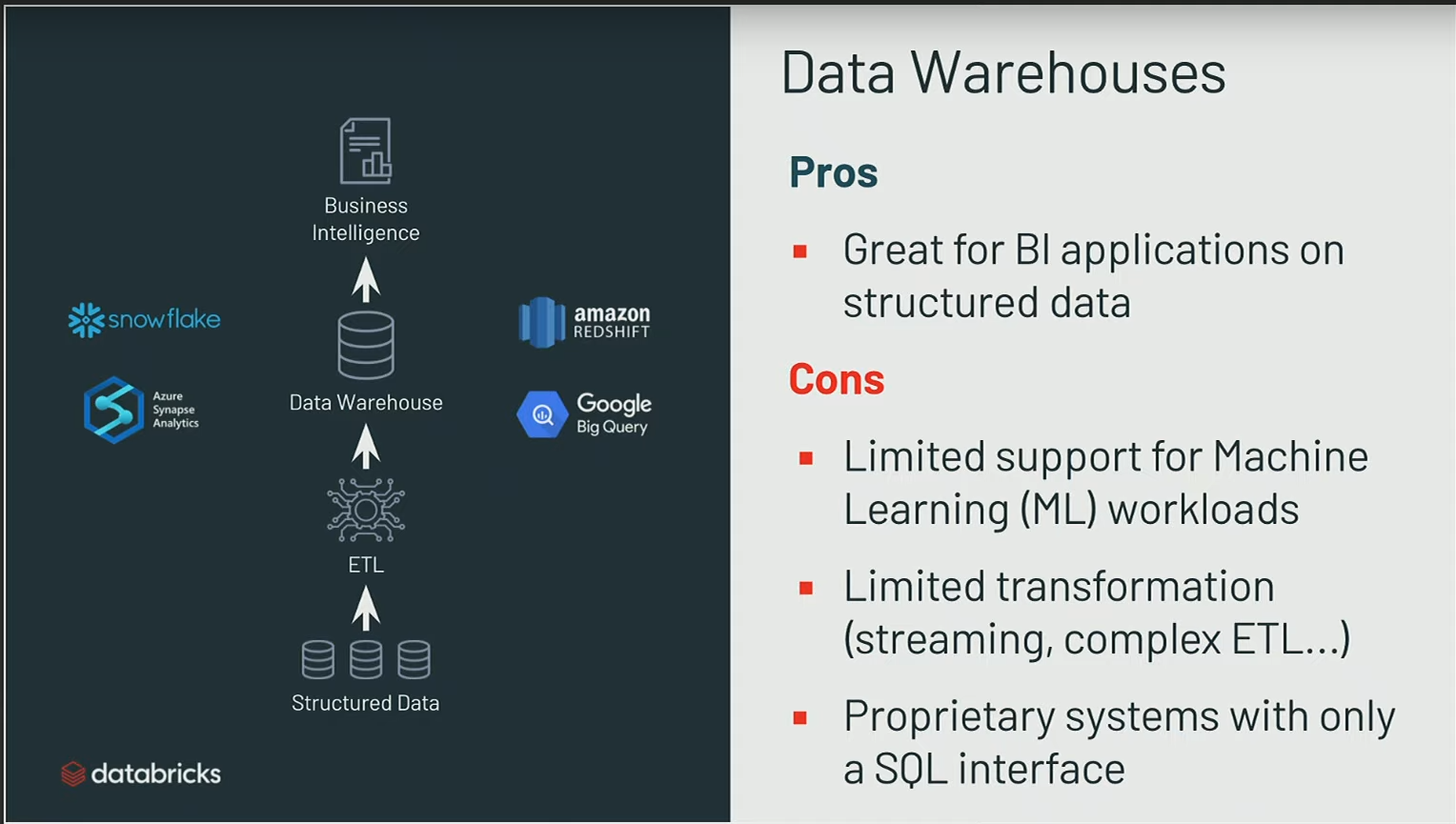
Cependant, malgré ces avancées, les data warehouses demeurent principalement orientés vers l’accès Business Intelligence (BI), présentant ainsi certaines limitations inhérentes à cette orientation:
- Les data warehouses ont été conçus initialement pour gérer des données structurées, idéaux pour des cas d’utilisation tels que le reporting sur des données opérationnelles. Ces systèmes ont bien fonctionné et continuent de bien fonctionner pour de tels cas d’utilisation.
- Cependant, avec l’évolution des besoins des entreprises, de plus en plus de projets incluent maintenant des éléments de machine learning, des données IoT, et des flux de données en temps réel. Ces technologies présentent des limites dès qu’il s’agit de traiter des données non structurées, des images, des données binaires, etc. Les data warehouses traditionnels ne sont pas adaptés pour répondre efficacement à ces besoins.
- Un autre défi réside dans la complexité des systèmes propriétaires liés aux data warehouses. Les entreprises ont souvent souffert de la rigidité de ces systèmes, où l’accès aux données est souvent lié à une base de données spécifique. La migration entre différentes versions peut être laborieuse, laissant les entreprises avec des systèmes fermés et difficiles à quitter.
Apparition et évolution des Data Lake
- Depuis 10 ans, émergence des data lakes avec des systèmes tels que Hadoop HDFS, Spark et Hive.
- Ces systèmes sont caractérisés par leur faible coût, open source, et promeuvent l’idée de s’affranchir des problématiques de verrouillage fournisseur (vendor lock) des DWH
- leur architecture distribuée permet une grande évolutivité, répondant ainsi aux besoins de scalabilité.
- Historiquement, la gestion des clusters Hadoop était complexe, mais cette complexité a diminué grâce aux services managés proposés par les fournisseurs de services cloud.
- Actuellement, on observe une prolifération de services managés autour de Spark, avec des plateformes comme Databricks. Ces services simplifient considérablement le déploiement et la gestion de clusters Spark.
Lorsqu’on se penche uniquement sur des solutions de Spark managées, elles résolvent certaines problématiques, telles que :
- Un support avancé pour les tâches de machine learning.
- Simplification des opérations de streaming et du traitement en temps réel.
Cependant, elles présentent certaines limitations :
- En ce qui concerne la BI à grande échelle, ces solutions peuvent ne pas répondre adéquatement en termes de Throughput.
- Elles ne satisfont pas toujours les besoins de low latency
- Les performances peuvent ne pas être aussi élevées que celles attendues par les entreprises, entraînant la nécessité de copier les données du data lake vers le data warehouse.
- Les problématiques de qualité des données se posent, car la nature flexible du data lake, qui accepte tous types de données sans contrainte de schéma, peut initialement être un avantage, mais se transforme parfois en un défi majeur. Cela peut conduire à des données de qualité médiocre, rendant difficile leur utilisation efficace.
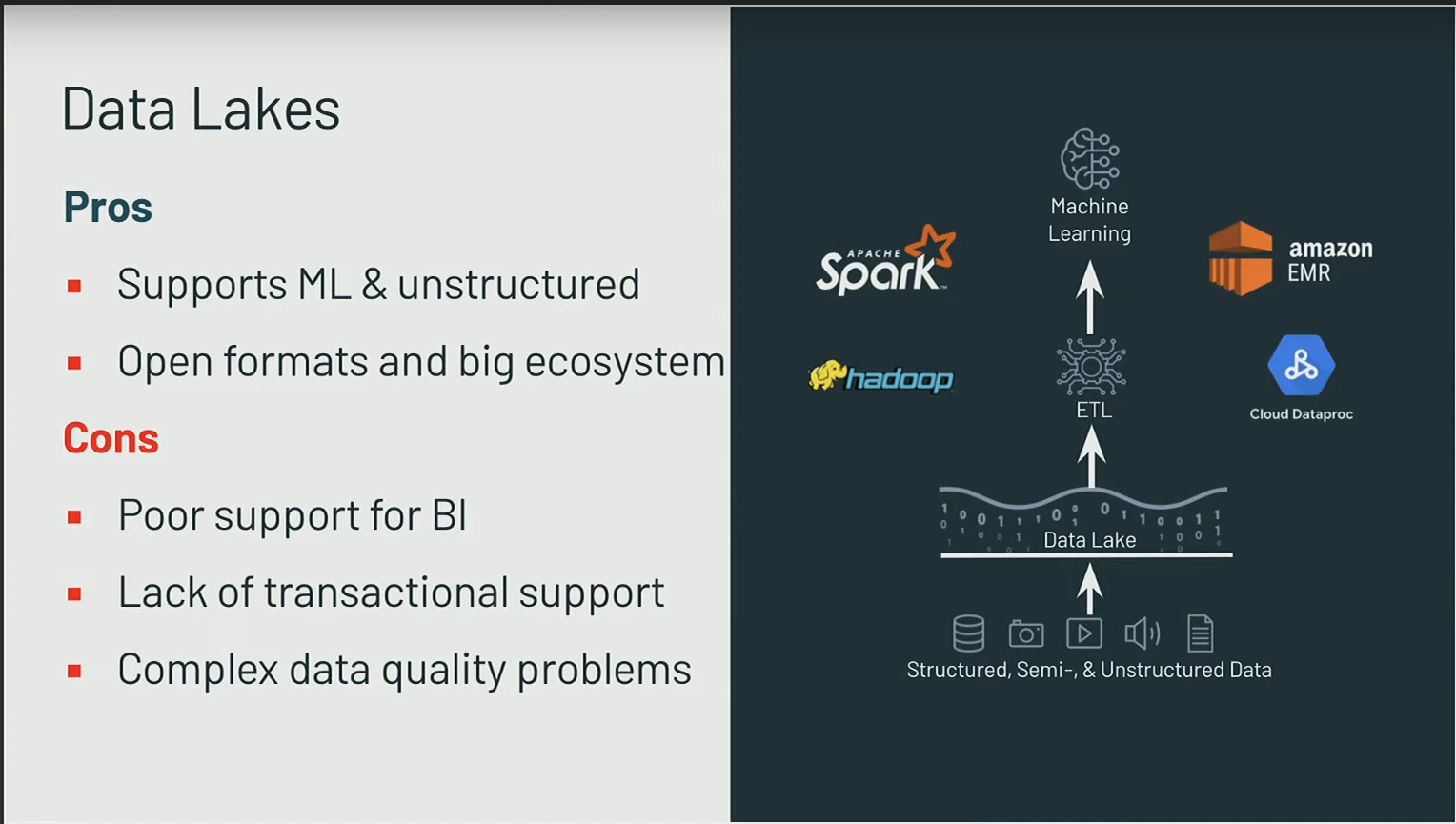
Ce que nous avons constaté, c’est que :
- La plupart des entreprises ont choisi de stocker leurs données, qu’elles soient structurées ou non, dans les data lakes en raison de leur coût de stockage abordable. Actuellement, environ 90% des données d’entreprise résident dans les data lakes.
- Initialement, l’idée était de traiter ces données, de réaliser des opérations ETL, d’implémenter des modèles de machine learning, et de permettre l’exploration des données en libre-service. Cette approche fonctionne bien.
- Cependant, pour livrer les projets aux utilisateurs finaux, il devient nécessaire de copier ces données et de réaliser des processus ETL. Souvent, il existe plusieurs copies de données, car chaque unité opérationnelle peut avoir son propre data lake.
- Les data scientists puisent dans le data lake, mais les résultats de leurs travaux doivent souvent être injectés dans les data warehouses.
Tout ce processus introduit des complexités telles que la gestion de la sécurité et la synchronisation entre les différents systèmes. Cette situation crée une véritable complexité et des silos, engendrant des coûts élevés pour les entreprises en termes d’infrastructure, d’outils et de ressources humaines.
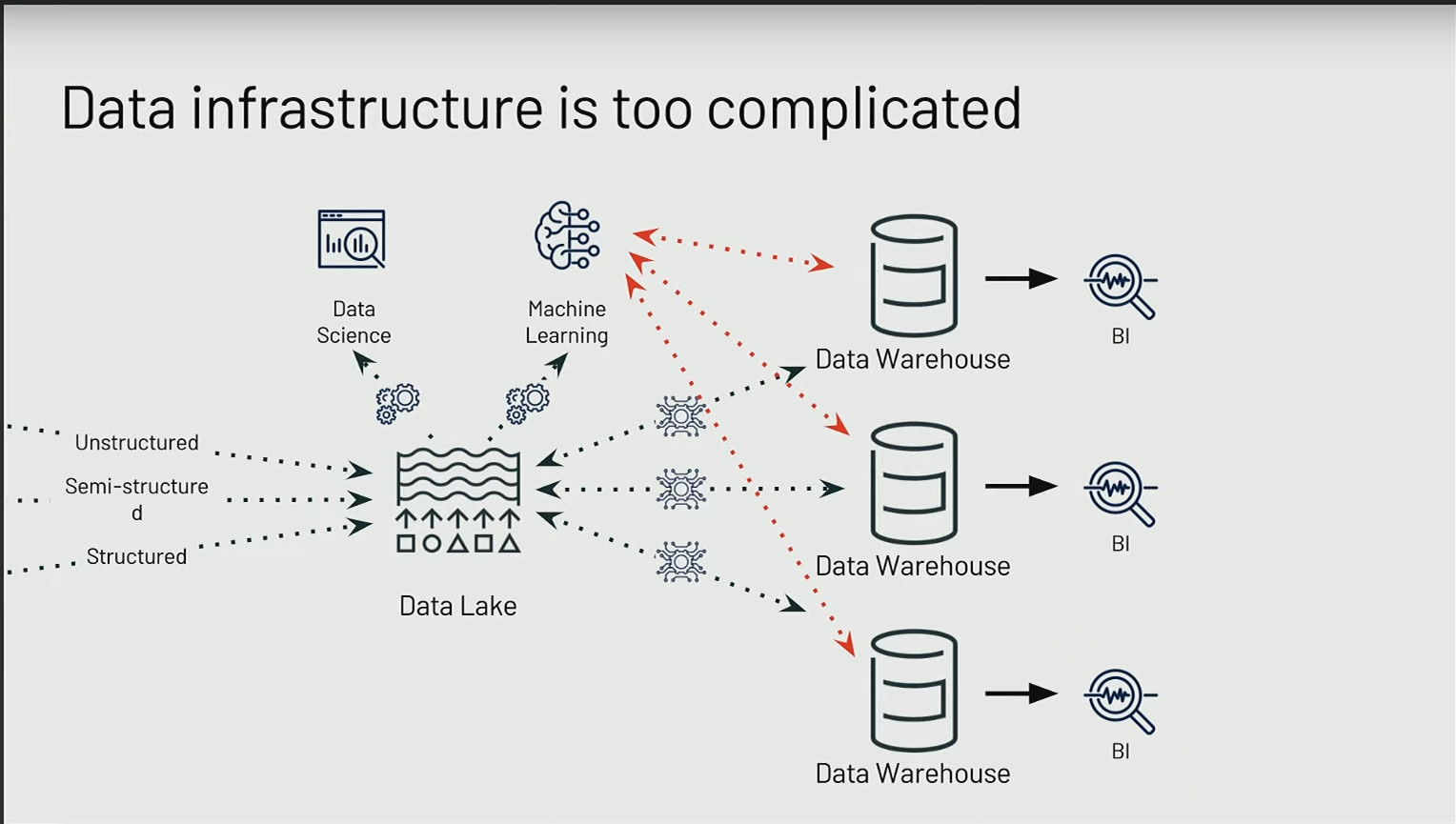
Le lake house
Pour améliorer la situation actuelle, une approche consiste à fusionner les atouts des data warehouses et des data lakes. L’idée est de créer une solution hybride qui combine :
- la performance et la qualité des données des data warehouses
- avec l’ouverture, la flexibilité open source, et le support du machine learning caractéristiques des data lakes.
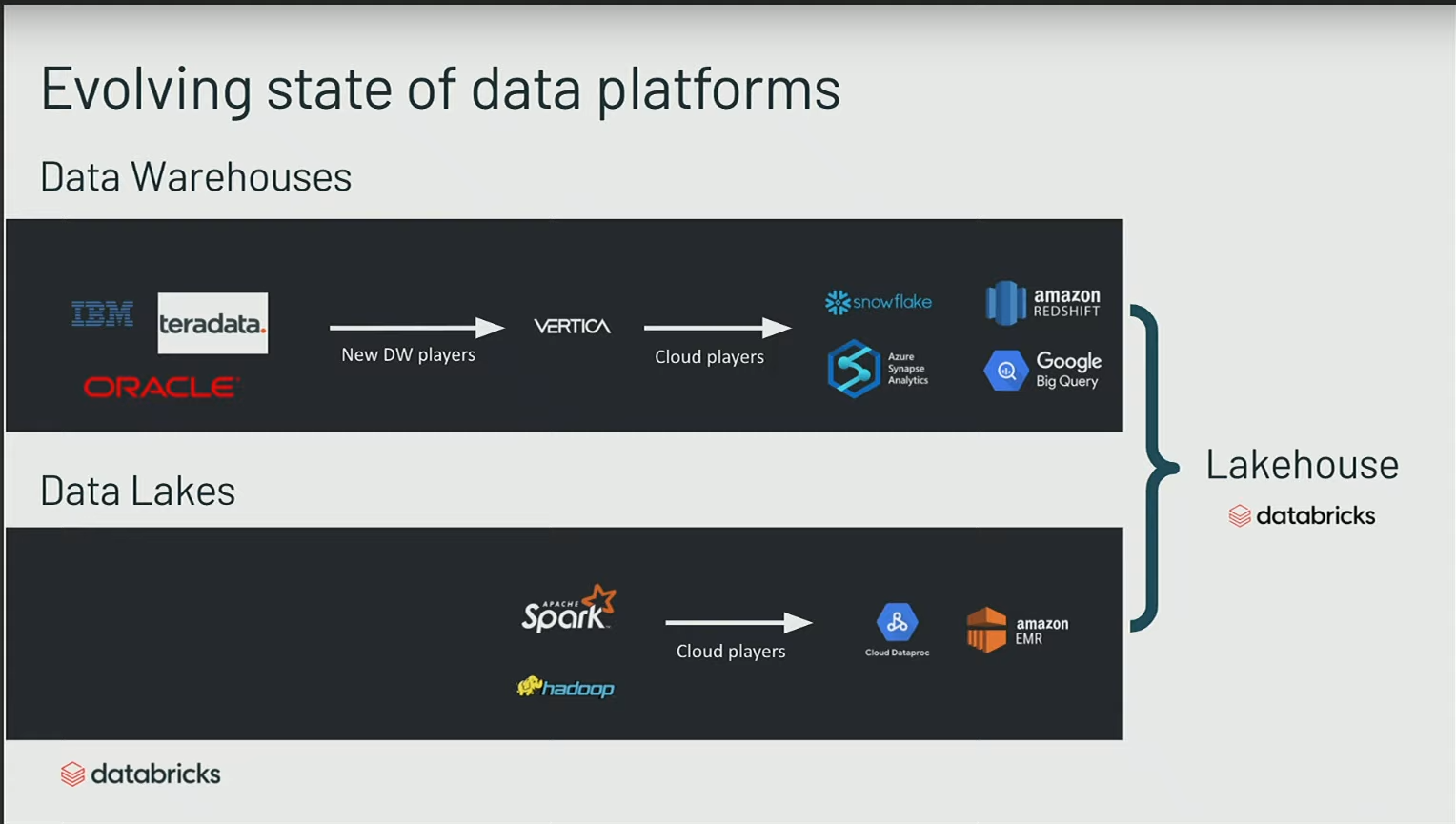
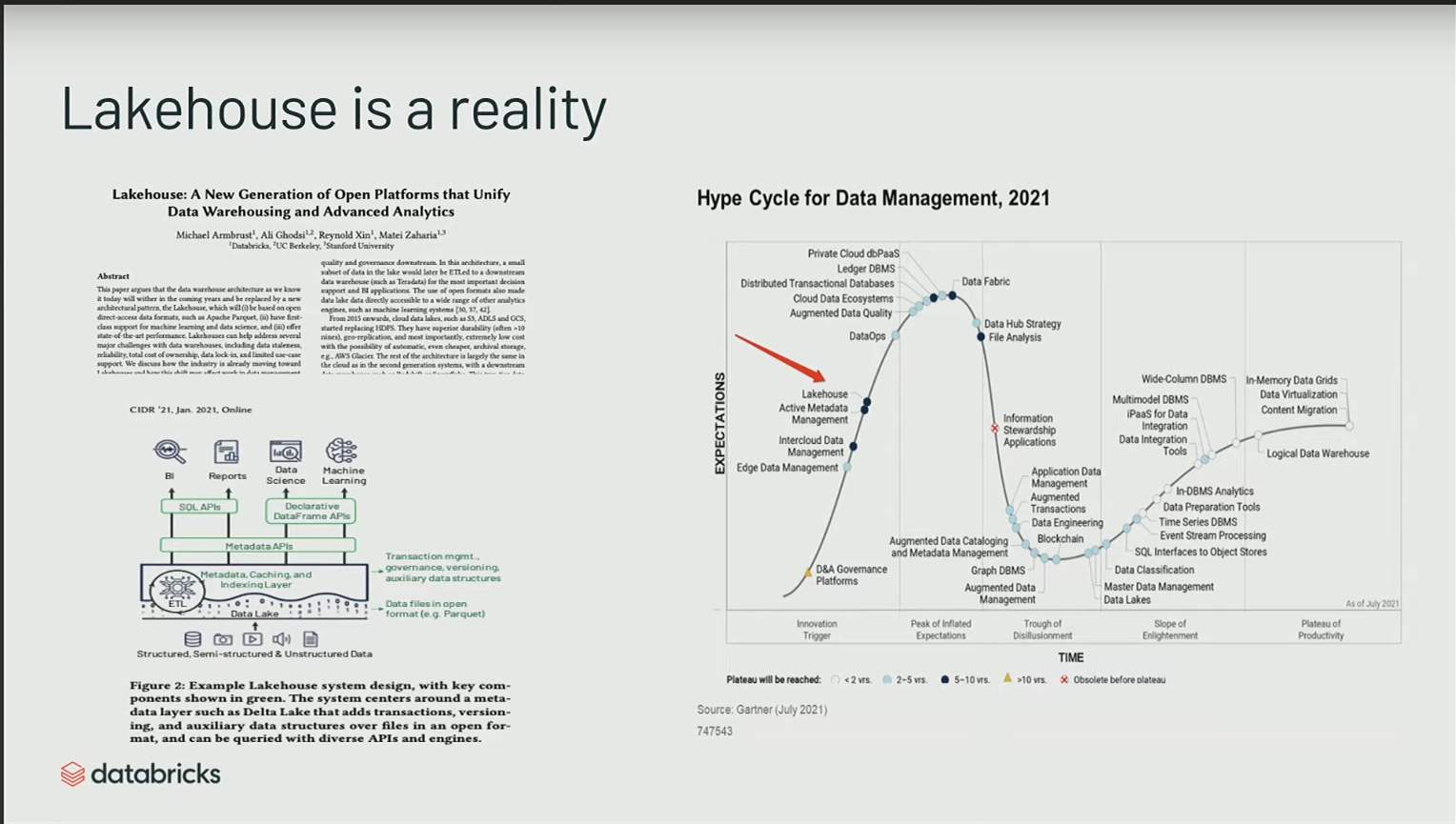
Le terrm “Lake house” n’est pas un terme ancien ; il a été popularisé il y a environ deux ans, principalement par Databricks à travers un blog et un article de recherche des créateurs de Spark, expliquant les concepts sous-jacents.
Ce qui fait vraiment la caractéristique du concept de lake house, c’est principalement sa couche de transactionnalité :
- Comment rendre le data lake ACID, en adoptant des caractéristiques traditionnellement associées aux data warehouses.
- Comment optimiser ses performances en termes de low latency et de high throughput, avec la capacité de requêter le système de manière extrêmement performante.
- La capacité de le requêter en SQL pour les analystes et les rapports.
- Mais en même temps, une approche déclarative, facilitant l’accès à ces données via des structures comme les dataframes Pandas.
Selon les prévisions du Gartner, ce paradigme devrait perdurer au cours des dix prochaines années. Il représente donc une direction vers laquelle de nombreuses entreprises commencent à migrer, cherchant à exploiter au mieux ces nouveaux schémas architecturaux.
Dans beaucoup d’entreprises on parle de lake house
- AWS,
- Dremio,
- Informatica
- Databricks
- Bill Inmon qui est un des fondateurs des datawarehouse et qui a sorti un livre sur le lake house
Building your own Lakehouse
Nous allons vous donner un exemple de ce qu’est une architecture lake house, avec les différents building blocks qui sont importants pour arriver au résultat souhaité.
Data Storage Layer
Dans cet exemple, on part d’un concept où l’on commence avec un data lake auquel ont été ajoutées les caractéristiques manquantes pour aboutir à un lakehouse. Ce n’est qu’une approche possible, et plusieurs entreprises ont plutôt opté pour une approche en partant du datawarehouse.

- La partie véritablement la plus importante et le pilier de cette architecture est la couche de stockage, constituée des données elles-mêmes. Pour obtenir une donnée fiable et performante, il est nécessaire d’avoir un système transactionnel, c’est-à-dire ACID, qui garantit la cohérence des données ainsi que la qualité de la donnée. Delta Lake en est l’un des meilleurs exemples.
- Le deuxième point est que cela fonctionne à l’échelle. On constate actuellement que, avec le volume de données à traiter dans les entreprises, il est nécessaire que cela puisse être mis à l’échelle. C’est un peu la caractéristique de Spark, qui est distribué.
- Le troisième point est la multimodalité. Il est essentiel que cela puisse s’adresser aux data analysts, aux data scientists, et aux data ingénieurs. Il doit être compréhensible par différentes populations afin de faciliter la mise en place pour différents cas d’usage.
Il n’y a pas que Delta Lake, il y a aussi d’autres systèmes, notamment dans le monde open source, tels que Iceberg ou Hudi, qui, tout comme Delta, sont des systèmes de fichiers apportant des caractéristiques et des fonctionnalités similaires.
Data Pipeline Engine

La construction de ces pipelines peut se faire à l’aide de frameworks dédiés lorsque l’on aborde le traitement des données. Dans le monde open source, on trouve des outils tels que DBT et Delta Live Table qui permettent de construire des ETL de manière à :
- Conserver le lineage (traçabilité) des données,
- Les opérer de manière simple,
- Mettre en place des mécanismes de retry en cas d’erreurs,
- Intégrer des règles de qualité des données et de cohérence,
- Documenter et découvrir de manière simple les différentes tables.
Unified Execution Engine
A ce stade, on dispose des données et des outils pour développer les pipelines, et maintenant il faut les exécuter.
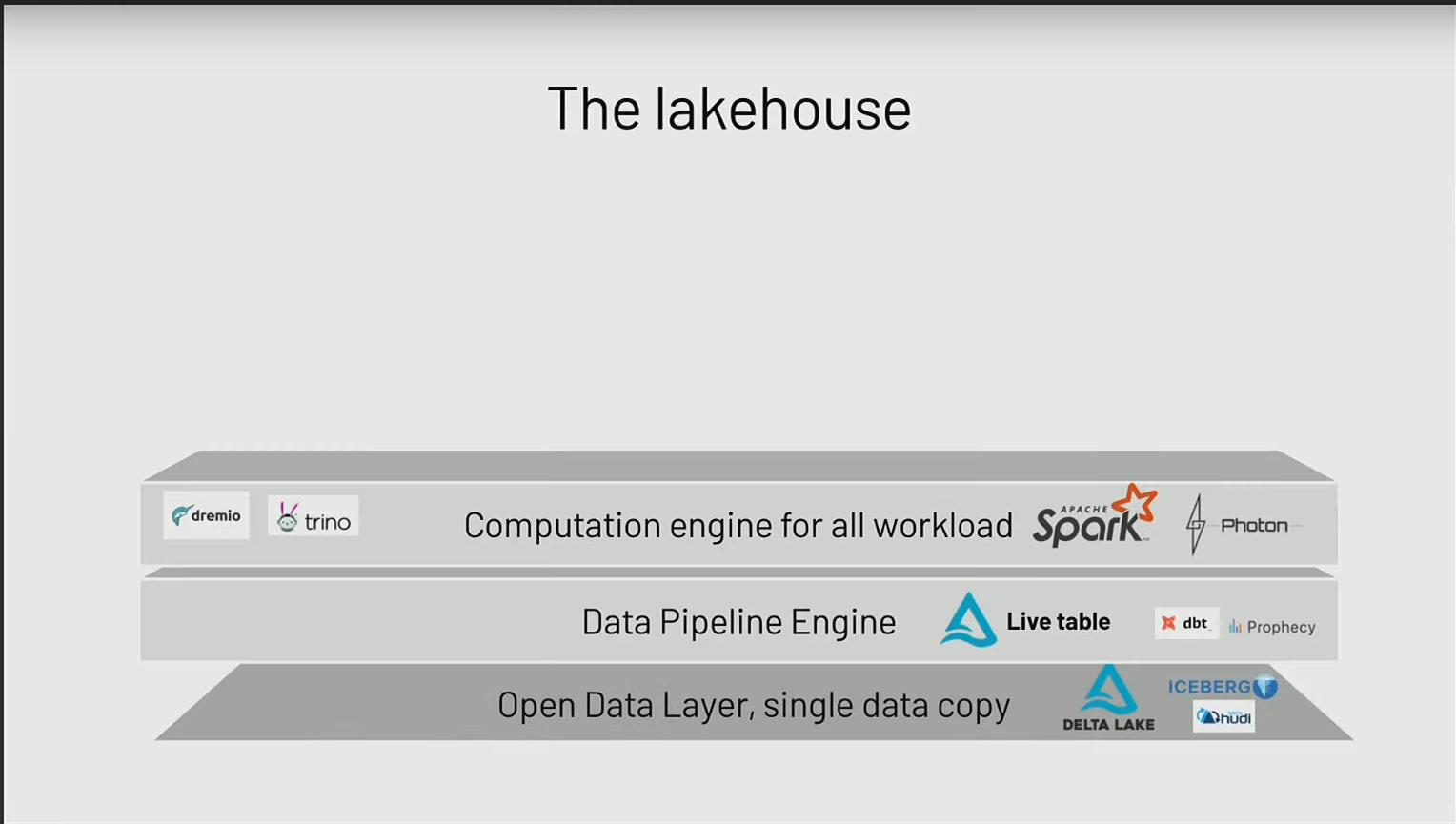
Pour les exécuter, le moteur devenu le standard est Spark pour tout ce qui concerne le traitement de données, et cela pour plusieurs raisons :
- Spark parle à plusieurs personnes ; on peut l’utiliser avec du SQL, développer ses pipelines avec du Scala, avec du R. Il supporte ces différents langages.
- Un autre point important est sa capacité à effectuer du streaming, de l’ETL et du batch. Spark unifie différents aspects, ce qui signifie que l’on n’est pas obligé de rester dans un seul univers. On peut passer du batch au streaming sans avoir à effectuer des modifications majeures dans les processus et l’architecture.
- Le troisième point, qui est crucial, concerne la scalabilité et l’élasticité. De plus en plus d’entreprises se tournent vers le cloud, où il est nécessaire d’avoir la capacité d’exécuter des workloads de manière serverless, de manière à pouvoir scaler en fonction des besoins, ce qui est le plus rentable pour les entreprises.
- Enfin, le dernier point concerne la performance. Être extrêmement rapide est un enjeu majeur, surtout dans le cloud. Plus l’exécution est rapide, moins cela coûte cher.

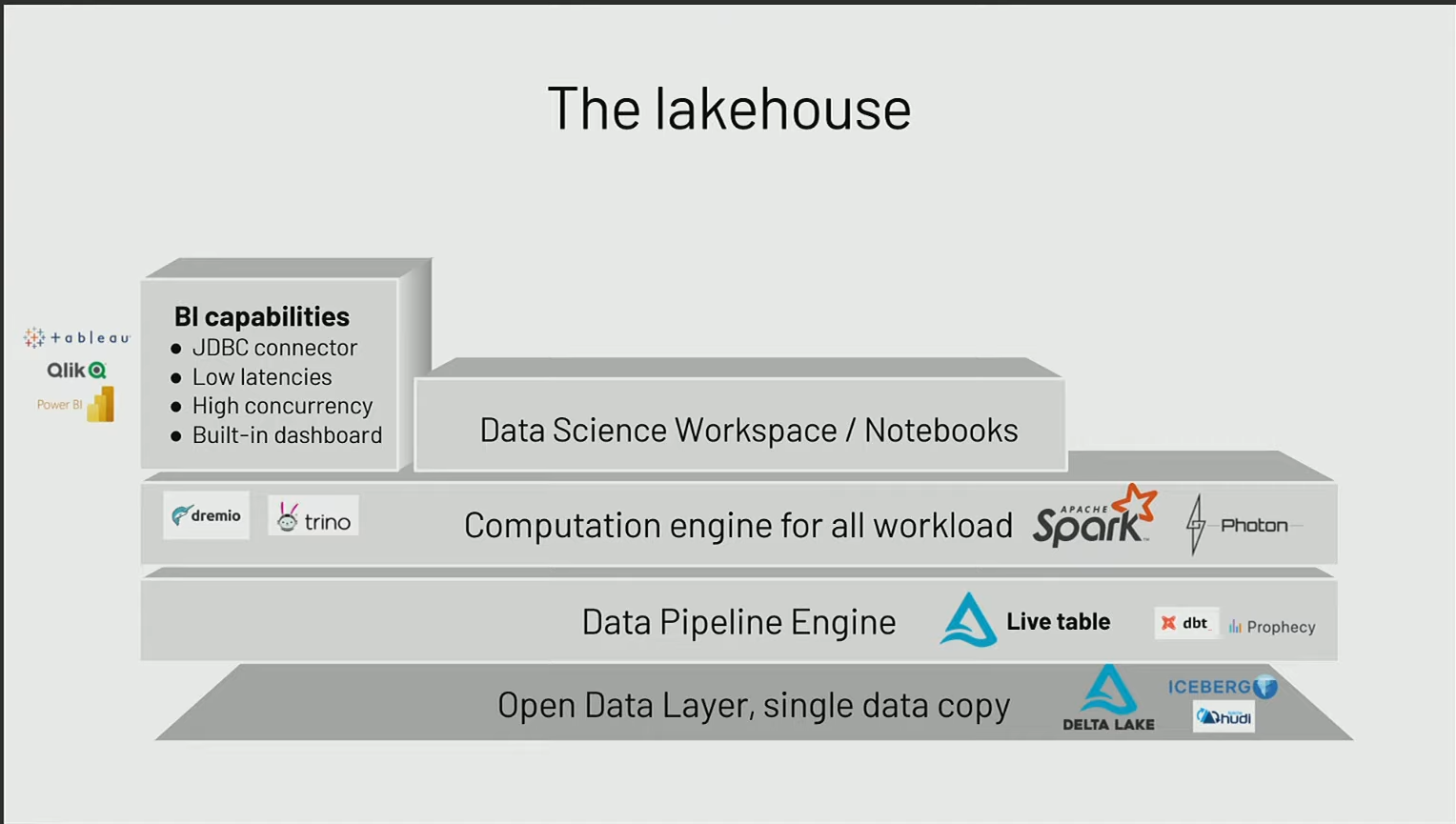
BI Capabilities

Le premier cas d’usage concerne la Business Intelligence (BI), et la question est de savoir comment connecter ces outils de BI. On préfère généralement utiliser des connecteurs JDBC, une approche classique utilisée par des plateformes telles que PowerBI, Tableau ou Qlik, permettant d’interroger directement les données.
Auparavant, cela posait des difficultés majeures car les performances des moteurs ne permettaient pas d’offrir une expérience utilisateur satisfaisante. Maintenant, avec Spark, on peut obtenir une faible latence (low latency) et une forte concurrence (high concurrency) directement au-dessus des données stockées sur le data lake, sans avoir à les copier et à les renvoyer vers un autre système de data warehouse pour les utiliser.
Data Science worksapace / Notebooks
L’autre point concerne un environnement de travail plutôt axé sur les data scientists, mais l’idée est de favoriser la collaboration entre les data ingénieurs, les data scientists et les analystes au sein d’un même environnement. Il est crucial qu’il existe un environnement de travail permettant à ces différentes personnes de développer dans le langage qui les intéresse, tout en bénéficiant d’un système de versionnage de code, et en utilisant les librairies qui les intéressent.
Machine learning lifecycles
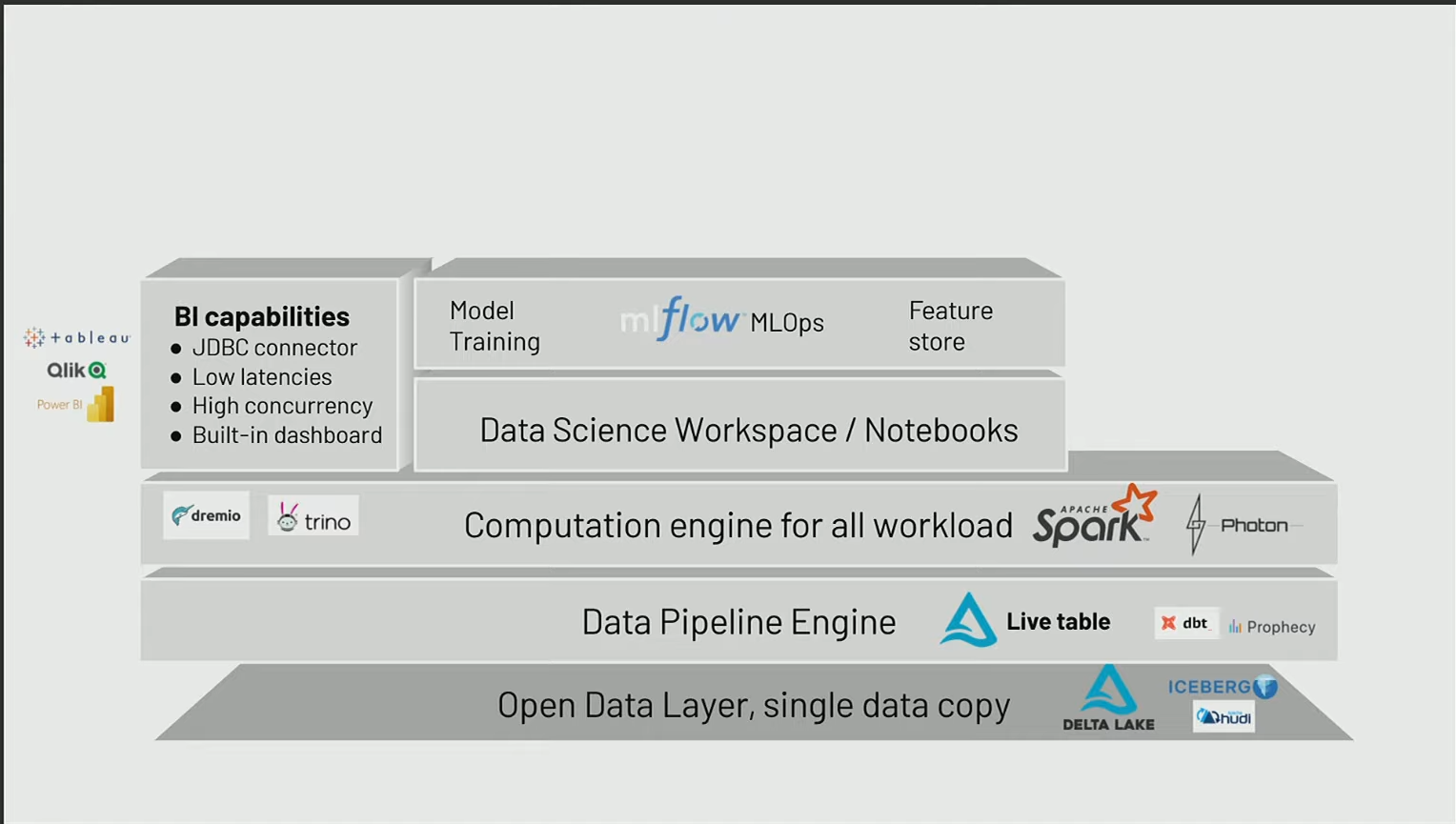
Si le premier cas d’usage est la Business Intelligence (BI), le deuxième concerne le machine learning. Lorsqu’on aborde le machine learning, il est essentiel de s’assurer que les projets puissent être industrialisés de manière simple. Il est nécessaire de pouvoir monter en échelle au niveau des projets, non pas du point de vue de la scalabilité de la performance, mais surtout en termes du nombre de projets. Comment peut-on être capable de gérer la gouvernance de ces projets de machine learning? Comment peut-on être sûr d’assurer le suivi des différentes expérimentations et des différents modèles déployés en production? C’est là qu’intervient, par exemple, MLFlow (ou Kubeflow)
Lakehouse to support Data Mesh
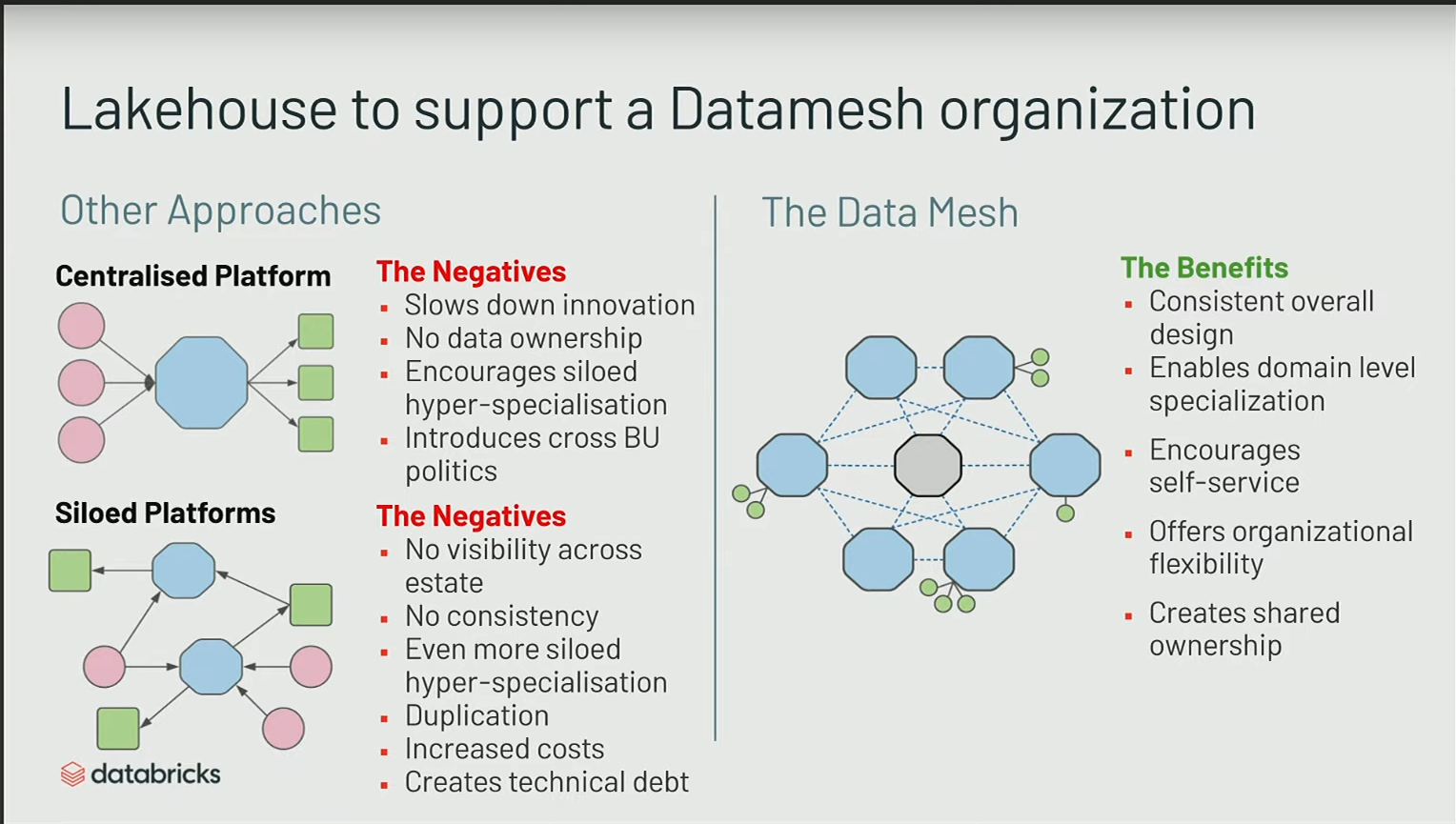
Si l’on examine ce que j’ai présenté sur le lakehouse, on pourrait penser que c’est une architecture très monolithique où tout est centralisé en un seul endroit.
En réalité, les architectures très centralisées ont existé et existent toujours, mais elles présentent un inconvénient majeur : on est obligé de passer par un bottleneck qu’est cette organisation centrale pour déployer différentes ressources et infrastructures.
Ce que nous souhaitons proposer, c’est une sorte de data mesh où les données peuvent vivre au sein de différents systèmes. C’est un peu comme plusieurs lakehouse au sein des organisations, où les données peuvent résider dans ce système de stockage et être partagées, accessibles depuis différents endroits.
L’intérêt est de maintenir une séparation entre le compute et le storage, et avec cette couche transactionnelle, nous nous assurons d’accéder toujours à la dernière version des données de manière fiable.
Le data mesh est davantage un principe d’organisation, et les lakehouse doivent être vus comme des enablers pour ce type de transformation organisationnelle, car c’est une architecture simple qui peut être déployée de facon automatisée (avec Terraform par exemple) et permet donc de créer facilmenet plusiseurs lakehouse
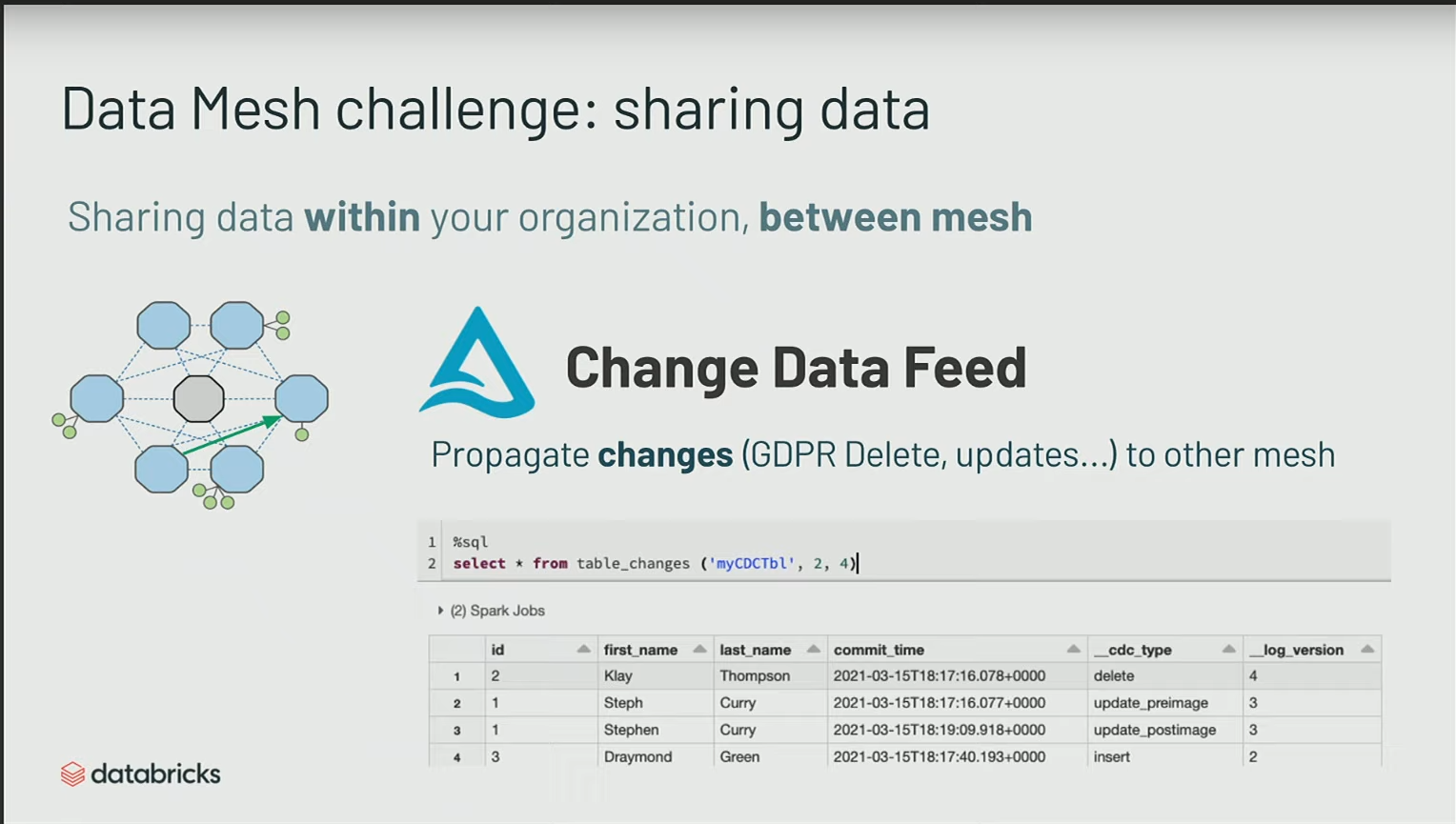
Une des features de Delta pour le Data Mesh est ce qu’on appelle le Change Data Feed.
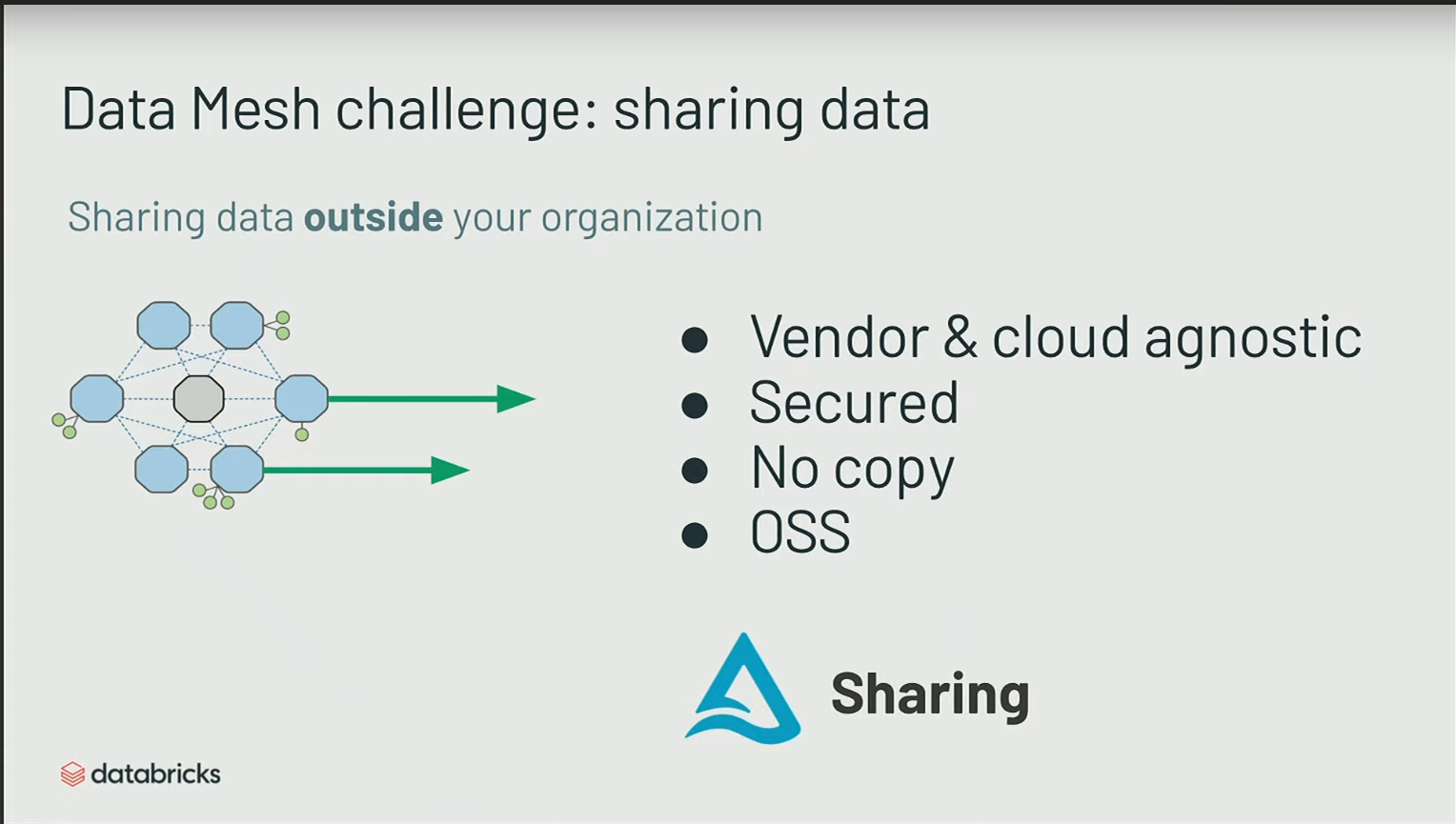
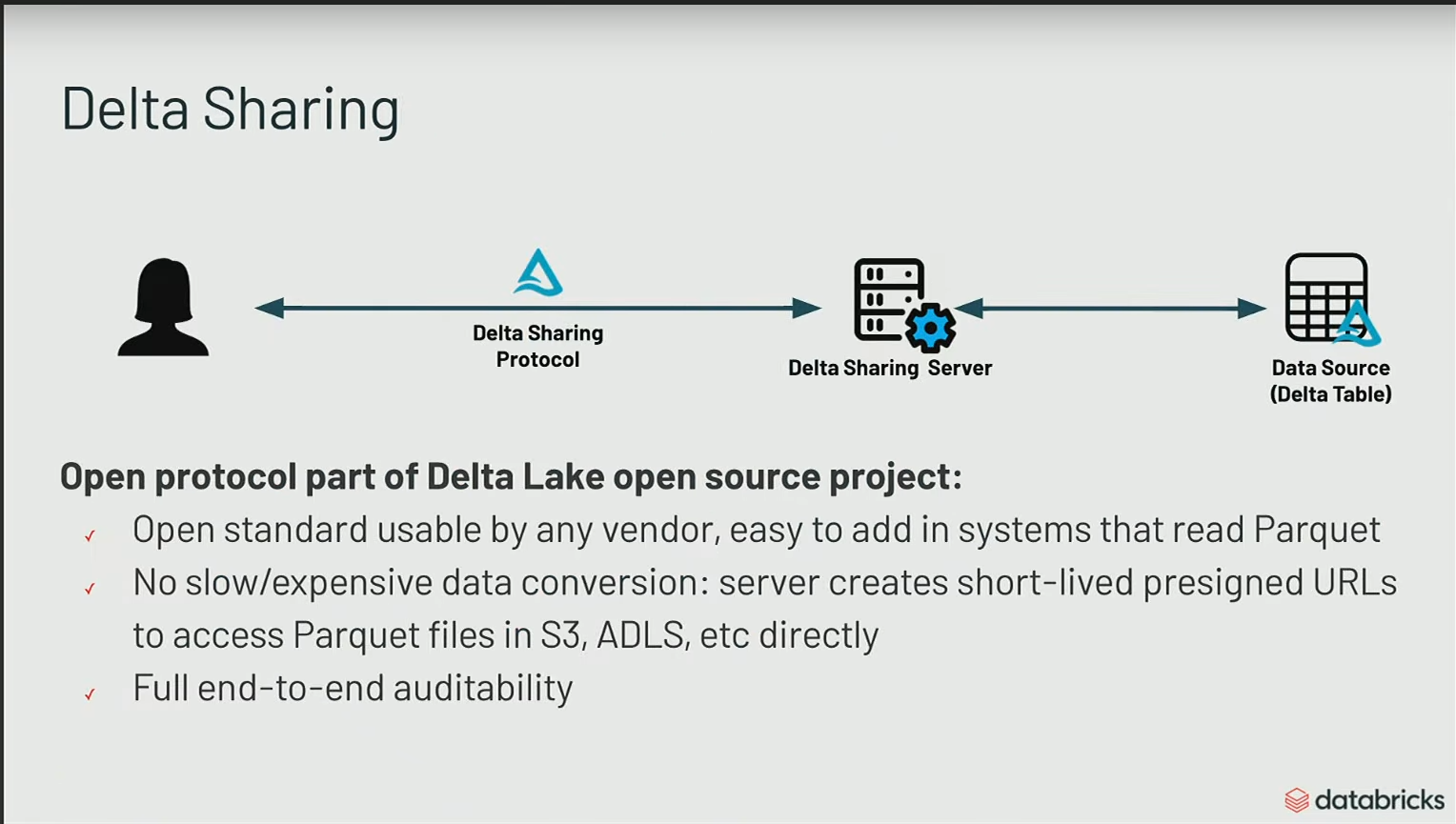
Delta Sharing est un système pour partager via un serveur aux partenaires
Governance
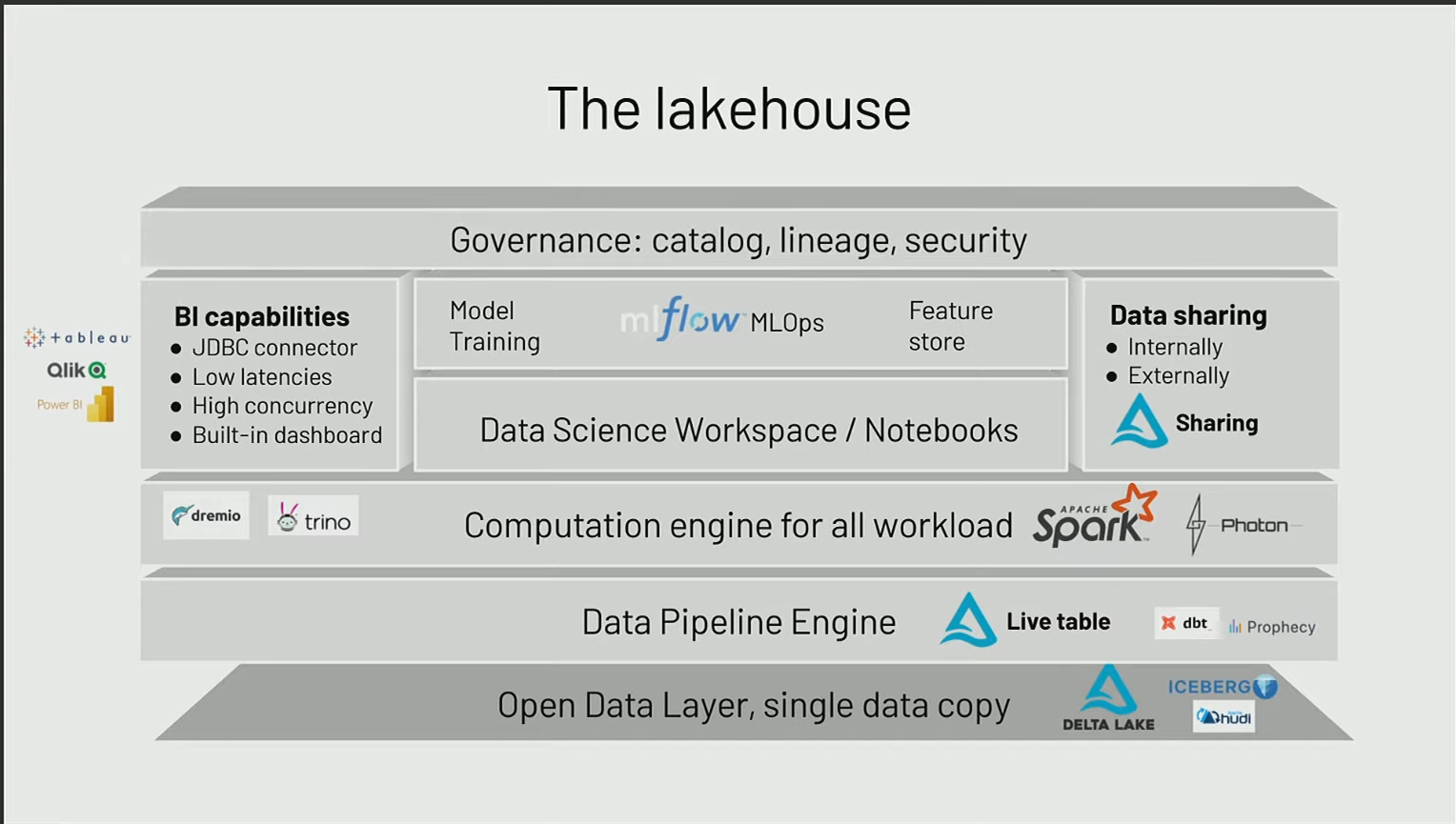
La dernière partie concerne la gouvernance qui permet de cataloguer les informations, d’observer tout ce qui concerne le lineage, et également d’appliquer toutes les règles de sécurité.
Conclusion
Datbricks offre un service managé de Lakehouse, mais Lakehouse est un pattern d’architecture, il y a d’autres implémentations. C’est un système en cours d’élaboration, un gors client comme Atlassian a mis un lake house en production.
